
Q: 8/14/2023 – 8/27/2023
R: 8/28/2023 – 9/10/2023
S: 9/11/2023 – 9/24/2023
NEON SIGN STORE PAGE: https://neonvisionsigns.com/
Summary: Long Post: There’s an entire writeup for my Git and Digital Marketing Courses I took recently in the notesdump below. Lots of pictures as well.
Once I finished building the Rat Rig, the belts snagged, and I had to rebuild the whole CoreXY system. Then, I cut the belts too tight, and had to buy better belts, and rebuild the whole CoreXY system. Then, the belts snagged again, and I had to rebuild the whole CoreXY system. I’m pretty good at switching these belts now lol.
During this time, I printed about a dozen benchies and slowly dialed in the settings. I was shooting for a sub 20:00 benchy, but the accelerations and speed got so high the frame was violently shaking. Definitely not good for the printer to be running that fast all the time.
I have plans to spend around another $1-2k upgrading and installing mods to improve capabilities and performance from the printer, but I want to work with it stock for a few months and get all the ducks in a row so the downtime is minimal.
I redesigned the channel system for the signs, and tweaked the way I slice the models. The result is something much easier and faster to print, that is also sturdier/stronger, and easier to assemble. It’s a bit bigger overall, but the speed of the rat rig still means things get printed at larger scale, faster.
Since organic orders have been pretty slow the last few months, I’ve had the opportunity to fulfill everything on my to do list and start doing some upgrade work. Since finishing the BJJ sign, the two Kobra Max printers have been in a state of total disrepair. I did some cleaning and calibrating and decided to just replace the hotends altogether. They both print great again. The Prusa makes some annoying noises, which I couldn’t figure out. Now both Kobras are in my closet and the Rat Rig is downstairs.
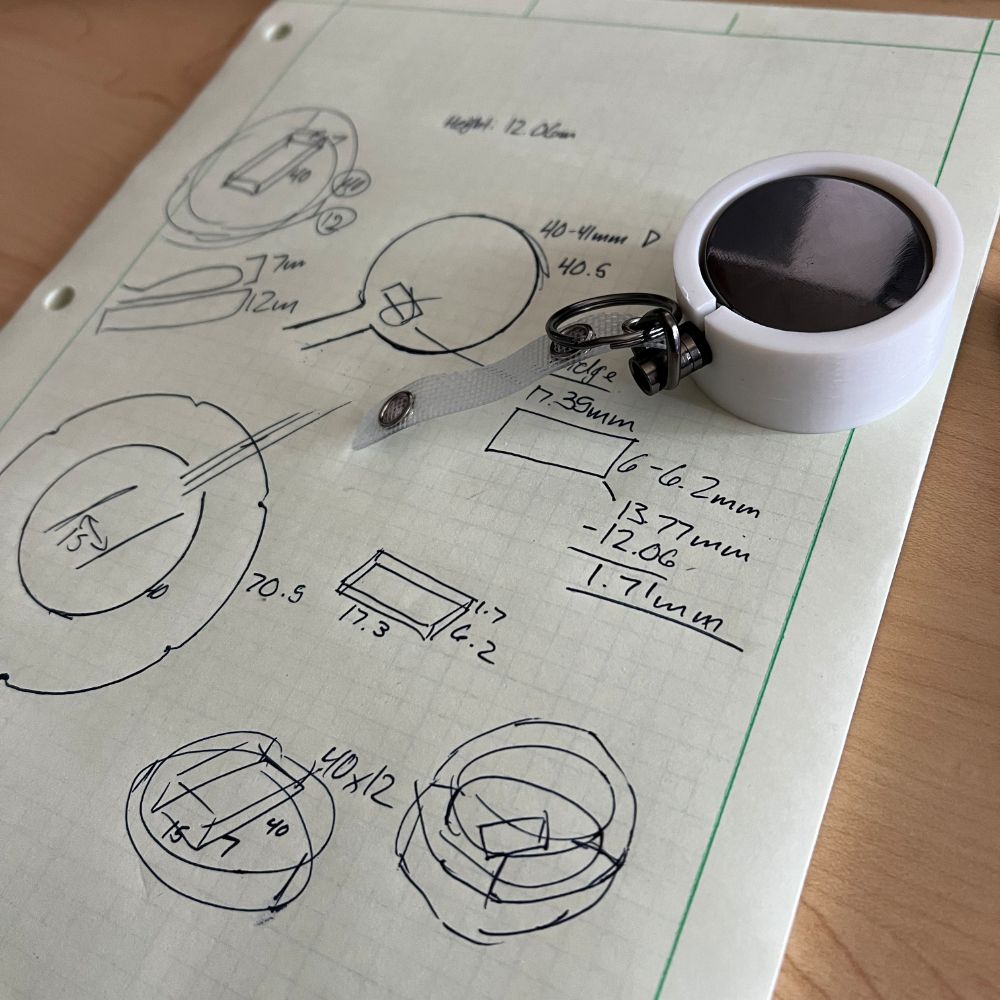
I’ve been commissioned to make some JoJo’s character Gyro Orb thing. It’s just a ball yoyo I made by sticking a retracting badge holder into a model of the orb and epoxying the whole thing together. It’s been a fun experience sanding, filling, and priming a cosplay prop though. I’ve been wanting to try that for a while now. I anticipate I’ll be print farming that soon.
The BJJ Sign’s power supply unit burned out due to thermal overload… in September. No idea why it took so long. Bought a different brand and replaced it, it didn’t last 24 hours. So I took the box home, bought a stronger dremel, cut it open, redesigned the vent, and installed two 12VDC fans on the panel and a large heatsink on the new PSU. Now it runs so cool the internal fan doesn’t even turn on. Feeling pretty good about that one.
I spent about two weeks watching Senator We Run Ads – Digital Marketing Foundations course on youtube. I learned a lot of specifics about nothing in particular. I’m so used to challenging myself by learning arcane electronical knowledge that learning something so cursory felt jarring and bizarre. It can’t be that easy right?
Anyway, after that, I decided I needed a website, so I made another website using the same framework this one is on: WordPress+Elementor, and linked a google form for the CTA/Conversion. Then I passed it around for review and critique, and collected some testimonials from my friends. The site is looking pretty good now. The latest step has been to commission some ad creatives so I can start marketing on FB/IG. I don’t have a lot of money in the business account at the moment, so I’m expecting to just sink personal funds into the marketing while I experiment and see what works.
I’m missing the coding and electronics study sessions, but I’ve decided the best use of my time is to see how far I can take the signs and see how much I can learn from them. I’m considering something like “Design and Order a new PCB every sprint” for 2024 to get more Done. We’ll see though, I like to change my plans a lot.

















































































































































































































QRS Post
Quagsire
Notes
Bringing in the Quagsire
Rat Rig Next Steps
ADD: Align Gantry
The gantry has a bit of play on the left
I’m reading that if you tension the belts properly you can get them to align
it is not going well
I keep overtensioning them and the belt is sliding out of the tooth lock
which is probably rubbing it down so it happens easier next time
frustrating, and hurts my hands
Lube all the Rails!!
Install Accelerometer, Configure
Pin Lineup
GND
gray
VCC
brown
CS
red
SDO
white
SDA
black
SCL
orange
Install 0.4mm Volcano + Spacer, Configure
Test Minimum Functional Part Fan Intensity (to lower volume)
Play with Acceleration + Other super slicer parameters
15k accel with stock gantry sooms to be a limit
Achieve 15:00 Benchy
Print Drag Chain for Cables
https://www.printables.com/model/186011
Just buy a drag chain
Then Print these mounts
—
From there
—
Rebuild Frame & Install Electronics Routing
Add Cooling to Mobo Steppers
Build Heat Set Insert & ERCF
Enclosure Panels
Timelapse Camera
Nozzle Camera
Mount LED Strip
48V PSU&Steppers
Carbon Fiber Gantry
—-
i ordered new belts because the belts are just too short to work with at this point
but the original belt was 5800mm and was to be cut in half to 2900mm
i can’t find 6m of the belt on amazon, so I had to buy 2x5m sections, which is pretty wasteful
but even after removing the belts I found that the free-sliding gantry still wouldn’t rest flush against the far end without pulling off and creating play
so I came to the conclusion that the gantry itself was too long
I pulled it off and found the printed joiner parts didn’t meet flush to the rail on the aluminum extrusion
which either means the prints are warped, or the aluminum is too long
my original assumption was that the prints were warped, and that the gap I was seeing between print and rail was indicative of the whole body being pushed out to 1mm longer than it’s supposed to be
but after reprinting the parts, that gap is still there, just a smidge smaller
since the gantry is 1mm longer than it’s supposed to be, it has to turn diagonally ever so slightly in order to fit onto the rails
this is what’s creating the one-sided slack when it’s installed, even before belts and tensioning
so i’m reprinting one side of the joiners with a deeper slot and if that doesn’t seem to create a better alignment issue, I’ll check the printed pieces that actually create the endpoint for the gantry
and if I need to, as a last report, I can always carefully measure the aluminum extrusion and see if it came out longer than it was supposed to
and then use the belt sander to rub off 1mm to size
but yeah the whole thing is like, super printer hell
this is the price of speed and performance
also, just learning a lot about corexy in general though so
I reprinted the joiner with a deeper slot and that made it so that the rail couldn’t shift anymore along the extrusion. It was perfectly snug.
Angel and I carefully aligned and mounted the gantry onto the y rail carriages and it was able to rest with no play on both sides without belts
I cut the new belts to length and slowly trimmed them down until I could achieve decent tension on both
And I was able to manage no play condition with belts on. After adding more tension there was a minimal amount, but much better than before
I was still seeing the shifting from loose belts on the print. I pulled on the belts while it was running and it got dramatically worse, so I assume it’s a tension issue
The belts are the exact right length right now
But when I went to tension them further
the lock nut inside the print that holds the belt ground out its hex slot in the print
meaning I couldn’t unthread or further thread
So I had to melt out the whole thing with my soldering iron to get pliers on the nut and torque it out
Which means I now need to order new lock nuts and reprint a few pieces of the hotend
It’s always something 🙂
Kobra Fixes
First, I figured out the underextrusion issue on the lower one
the gearbox was full of shredded filament, so I disassembled and cleaned it
Then, I realized that the standard 0.4mm nozzles won’t work with this printer. it jams and clogs up
I had to clean a lot of filament out of the heat block and then reinsert the original volcano-length 0.4mm nozzle for it to work
but it does work properly now
Going to wait to fix the other one until the new 0.4mm volcanos show up
Then replace both
I read on the rat rig mod vid that the volcano nozzle is just flatly better with no downsides, so I’ll pull that extra spacer out of the phaetus box and install a 0.4mm volcano into the rat rig on wednesday/thursday during the next build session as well.
—
Still didn’t work, so I just ordered two new heatblocks for the whole thing, since I’m guessing they’re gunked up or damaged
between the new heatblocks and new nozzles if they still don’t work I’m kind of at a loss
I’m pretty sure the A printer’s bed is warped a bit in the center as well, and I’m not sure what to do about that since its auto bed leveling doesn’t seem to catch it
—
both are behaving much much better, near perfect after replacing both hotends
which I’m grateful for
now to dial some stuff in so I can actually print the hot wheels print
old start GCode
G28 ;Home
G1 Z15.0 F1200 ;Move the platform down 15mm
;Prime the extruder
G92 E0
G1 F200 E3
G92 E0
new start GCode Test 1
G28 ; Home all axes
G92 E0 ; Reset Extruder
G1 Z2.0 F3000 ; Move Z Axis up little to prevent scratching of Heat Bed
G1 X10 Y.5 Z0.3 F5000.0 ; Move to start position
G1 X100 Y.5 Z0.3 F1500.0 E15 ; Draw the first line
G1 X100 Y.2 Z0.3 F5000.0 ; Move to side a little
G1 X10 Y.2 Z0.3 F1500.0 E30 ; Draw the second line
G92 E0 ; Reset Extruder
G1 Z5.0 F3000 ; Move Z Axis up little to prevent scratching of Heat Bed and let out nozzle pressure
G1 X0 Y15 Z0.4; Move back to heat bed, sticking blob of filament down before travel move to free nozzle
Prusa Fix
g1 x-100 y-100 f4000
g1 x100 y100 f4000
the +x -y direction was the noisiest
I greased all the rails manually with a paper towel, retensioned the belts
and manually cranked both lead screws up to max to make sure they were even
the printer is much quieter now
I also found the old nozzle in the well of the left lead screw, which was probably creating issues lol
Experiencing some Gantry Racking
Git & Github Bootcamp
Summary
Git Core
Overview of Git
Git is Version Control Software. You do it in the terminal
Github is a code hosting platform
GitKraken is a GUI for Git Repos. It’s very useful.
Git infects folders and turns them into repositories
Repos contain chained branches consisting of individual commits. Every commit has a commit message.
You should never initialize a repo inside a repo
There’s three zones in a repo
Working Directory
Stuff you’re working on now
Staging Area
Stuff you’ve prepared to commit
Repository
All the stuff you’ve ever committed
There’s a hidden .git folder that manages everything behind the scenes
Git docs will drive you insane. It’s too complicates.
Commits should be Atomic. They consist of one and only one change. This keeps commit messages simple and timelines legible.
The .git folder contains a .gitignore file for ignoring files. This is more useful than it sounds
Every commit has a unique ID, a hash, and references at least one parent commit, sometimes two.
Git has branches so commits can be made onto different timelines. Branches can be merged and deleted
Branches behind the mask are just pointers pointing to a commit.
Whatever commit you’re currently on is determined by a pointer called HEAD.
HEAD prefers to point at branch pointers, rather than at commit hashes directly.
If it’s pointing at a commit hash directly, it’s a detached HEAD.
The branch & commit you are on when you create/delete/merge a branch matters.
The branch specified in the merge command gets merged INTO whatever branch you’re currently on.
When a merge can’t be completed automatically due to conflicting info from the two sources, you have to manually resolve this in a text editor.
Commands – Git Core
git status
check the status of the repo you are in
git init
create a repo inside the current directory
git add <file>
this is how you move files into the staging area when preparing for a commit
git add .
this is how you quickly add all files to the staging area
git commit -m “commit message”
this is how you create a savepoint on the timeline. it takes all the recently changed files that have been “add”ed to the staging area and takes a snapshot you can refer to and return to. commits require commit messages, preferably written in present imperative tense
git log
prints a list of all the commits in a repo
git log –oneline
more condensed version of git log
git config –global core.editor “code –wait”
Sets global config to use VSCode as your text editor for git functions
git commit –amend
Lets you add files that were forgotten to the most recent commit
git branch
lists all branches in the repo. active branch will be * marked
git branch <branch-name>
creates a new branch. Does not switch you to it. no spaces in branch names.
git switch <branch-name>
Switch branches
git checkout <branch-name>
exact same functionality of git switch. more old school.
git switch -c <branch-name>
Create a new branch, and switch to it.
git checkout -b <branch-name>
Create a new branch, and switch to it. more old school.
git switch -d <branch-name>
Deletes the branch. You can’t delete the branch you’re on. (should be merged)
git switch -D <branch-name>
Forcefully deletes a branch.
git branch -m <new-name>
Renames the branch you’re currently on. You can target another branch as well.
git merge <branch-name>
Merge the specified branch into the active branch
Next Level Git
Diff
Git diff shows you the difference between two files using a Syntax called Chunk Headers. It just shows you both versions of the file at the point of conflict.
GUI Tools are great for viewing diffs. Terminal is clunkier.
Stash
Git stash lets you stash your WIP code like a little raccoon. Clear the table so you can go check out some other branch, etc. You can pull it back out later. Like a quick pocket.
Technically, you can pop out those changes on another branch, somewhere they weren’t meant for. You probably won’t ever do that though.
Checkout
Git checkout does everything. It did so much everything they had to make up new commands to make things easier to work with that do all the same things.
You can enter detached HEAD on purpose with git checkout. When you do this, you can’t make permanent changes unless you create a new branch from that point.
detached HEAD is kind of like time travling. You get a snapshot of how the timeline used to look at that point.
Restore
Git restore discards changes on a particular file and reverts it back to last commit. This command is not undoable. You cannot get the discarded changes back.
Reset
Git reset doesn’t actually reset the code, just the commit history. If you want to reset the code too you have to –hard reset.
It’s pretty much always better to add to the timeline than it is to remove, since other people are liable to look at it and keep their own version of the timeline that will get confused when they look at the one you chopped up
Commands – Next Level Git
git diff file1 file2
Render the differences between the two files
git diff
Will show unstaged changes vs. HEAD
git diff HEAD
Will show staged changes vs. HEAD
git diff –staged
Will show ONLY staged changes vs. HEAD
git diff HEAD file
Will show only the changes vs. HEAD for a specific file
git diff branch1..branch2
Will diff every single file between two branches
git diff commit1..commit2
Will diff every single file between two commits (commits are referenced via hashes)
git stash
Reverts your working directory back to match the last commit/HEAD
git stash pop
Replaces the current working directory with whatever was stashed before
git stash apply
Applies the stashed changes to the current HEAD, even if on a different branch. Does not clear the stash.
git stash list
Lists all the stashed sets of changes
git stash drop stash@{2}
Deletes the stash from two stashes ago
git stash clear
Deletes all stashed changes
git checkout HEAD~1
Will checkout whatever commit came immediately before the current one
git switch –
Will reattach head by switching to whatever branch you were on before detaching
git checkout HEAD <filename>
A quick way to revert a file to base after making changes
git checkout — <filename>
Same function
git restore <filename>
Reverts file back to last commit (Same Function)
git restore –source HEAD~1 <filename>
Reverts file to whatever it was the commit before last
git restore –staged <filename>
Removes file from staging area (un-adds)
git restore –staged .
Clears entire staging area.
git reset HEAD~1
Deletes most recent commit and moves repo back one. Retains file changes
git reset –hard HEAD~1
Deletes both commit and changes. Reverts repo back one commit.
GitHub/Collab Core
Cloning and Pushing
GitHub is the entire world
You make repos on github, and then connect them with your local machine’s repo. The system is called “remotes”. Remotes are just urls pointing to another version of the repo.
You can push code to a remote, or pull code from it.
When you want to download your code or anyone else’s from GitHub, you use git clone, and create a local version of the repo on your computer.
Workflow
1. Create empty repo on github
2. Clone down onto local machine
3. Make changes and push back up
GitHub will tell you how to do this on the webpage when you make a repo.
When you push code, you push an entire branch at once. But not all branches.
Workflow for pushing code
(Make Changes)
>git add .
>git commit -m “message”
>git push origin master
There’s a distinction between the branches you have locally and the branches you have on github. Even when they have the same name. You’re pushing local master up onto remote master
Git has “remote tracking branches”: additional branch pointers that remember which commit each branch was pointing at on the remote version of the repo the last time you went online and interacted with it.
When you clone someone else’s repo, you won’t have all the branches. But if you switch to a branch name that matches an existing remote tracking branch, Git will automatically set up that branch locally and link it to the remote version.
Fetch and Pull
Git Fetch and Git Pull are different
Fetch will clone the most recent version of the remote repo into the LOCAL REPO
Pull will clone the most recent version of the remote repo into the WORKING DIRECTORY. Meaning when you Pull, you lose your work.
Pull will move your HEAD. Fetch will not move your HEAD
Pull is basically a combo of fetch and merge. Meaning it can and will create conflicts.
Fetch is for when you want to keep working but want to stay up to date.
Repo Config & Other GitHub Features
GitHub repos can have visibility whitelists, and collaborators can be added with mutual consent.
Every GitHub Repo will contain a README.md file giving the tl;dr of the project.
Pertinent information to include in README
what the project does
how to run the project
why it’s noteworthy
who maintains the project
GitHub also has gists which are lightweight snippets of code like pastebin.
GitHub also has pages which are just static frontends. You can have a page for each project, one per repo. You also get one page for your whole profile, independent of the repo. This can act as a portfolio
Collaboration Methodologies
Understanding the Collaboration Workflows are critical. It’s what takes GitHub beyond mere version control and turns it into the world eating collaboration monster.
Forcing everyone to work on just one branch is literally unplayable.
Instead, people treat the master branch as gospel and protect it with their lives. They create feature branches whenever they need to do or try something new. Once the feature is complete, they merge it into the master branch with the authority’s permission.
This is called the Feature-Branch Workflow.
No new work is done directly on the master branch. When managed properly, the master branch will never contain broken code.
Feature-Branch Workflow
Pull the latest changes from remote master
Create a local feature branch
Build out the feature, make some commits
Switch to master
Pull the latest changes from remote master
Merge the feature branch into master
Resolve conflicts if any
Push master up to remote
Delete any local or remote instances of the feature branch
Pull Requests are the social mechanism by which we submit changes for approval.
“i have new stuff i want to merge into master. what do you think?”
The Master branch can and should be protected. Nomenclature rules for feature branches can also be enforced automatically by GitHub
Pull requests can be made from a branch on one person’s repo to a different branch of a different person’s repo.
Pull Request Workflow
Do work locally on feature branch
Push feature branch to github
Open a pull request to the feature branch you just uploaded
Wait for the PR to be approved and merged. start a discussion. team structure stuff. etc.
When there are merge conflicts in a PR, it is necessary to clone a copy of the new code onto local, resolve the conflicts, ensure the merge will go through without issues on master, and then push the cleaned version up to the remote on GitHub
PR Conflict Resolution Workflow:
Acquire feature branch, resolve conflicts
git fetch origin
git switch feature
git merge master
Fix conflicts
Merge feature conflictless, push to GitHub
git switch master
git merge feature
git push origin master
Because collaborators have to be added to GitHub repos manually, there exists a superstructure where everybody can have their own version of the repo on GitHub from which they can submit pull requests from their version into the original. This is called Forking.
You’re not cloning the repo onto your machine; you’re cloning the repo into another repo that you control. Which you then clone onto your machine.
This system enables anybody to go play with and spin off anyone else’s code without the need to ask for permission. This is also how thousands of people can contribute to a project without formal organization (open source)
Commands – Collab Core
git clone <url>
Downloads and inits a local copy of the repo referenced in the url
git remote -v
Lists the remotes/destinations the repo knows about
git remote add <name> <url>
Adds a remote destination for pushing and pulling associated with name and url
git remote rename <old> <new>
Rename a remote
git remote remove <name>
Remove a remote
git push <remote> <branch>
Pushes a branch’s local commit history onto the remote repo
git push <remote> <local-branch>:<remote-branch>
Push a particular local branch onto a particular remote branch
git push -u <remote> <branch>
Push a local branch to a remote, and set the default destination for that local branch
git branch -r
Will list the remote tracking branches in the repo
git switch <remote-branch-name>
Creates a local branch matching the name of a remote branch and sets up tracking
Git: The Other Parts
Rebase
Git rebase lets you rewrite a commit history in a cleaner way.
It’s good for cleaning up your local timeline before you push a feature branch up. If you rebase a timeline that other people have already accessed, you’re going to confuse everybody’s machines as the timelines get confused.
Do not rebase anything that has already been pushed.
Rebasing’s main use case seems to be cleaning up periodic merge commits sprinkled into a feature branch’s commit history. Rebasing recreates all the novel branch commits onto the most recent master commit.
It’s a good practice to create a new branch and switch to it before doing the rebase, so you can keep a copy of the non-rebased work just in case.
Rebase has an interactive mode where you can tweak commits in detail. This takes place in the text editor.
List of Function Words
pick
use the commit
reword
use the commit, but edit the commit message
edit
use the commit, but take a moment to amend the commit
fixup
use commit contents, but combine it with previous commit and discard this one’s commit message
drop
remove commit from history
Tags
Git tags are not difficult and uncommonly used. They are de facto only used for Semantic Versioning.
Semantic Versioning
Semantic Versioning is a software standard, like a benchmark that software can be observed to comply with. There’s a defining document and all that.
Semantic Versioning consists of three numbers: v1.2.3
1 is the major release.
2 is the minor release.
3 is the patch.
For patch changes, the alterations should be small and should not disturb or break existing functionality.
The minor releases will include new features and moderate changes but still retain backward compatibility.
The major releases are where significant changes are made, features might be removed, and backward compatibility is broken.
The 1.0.0 version is when the official, public-facing API is defined. So, if there’s not a complete public release that non-developers can be expected to use, it’s not 1.0.0 yet.
A tag is just another pointer, like the branch reference, but it points to a single commit and never changes. Just a label for a for a particular commit.
There are two types of tags
Lightweight Tags
Simple
Annotated Tags
Contain metadeta: tag name, user name, pusher name, timestamp, tag message
When you push your local repo up to GitHub, by default, tags are not going to be included. You have to push –tags
Under the Hood
Contents of .git:
Objects folder
There are 4 main types of git objects
commit
tree
blob
annotated tag
They’re all encryped by SHA-1. This is how the hashes are generated
All the data is stored here. Everything outside the objects folder is just an elaborate network of pointers.
Refs folder
Branch pointers, tags, etc. are all stored and exist inside refs
These files contain just the commit hash of the commit they point to. They are the branch pointers
config file
index file
HEAD file
Hashing & Encryption
Hashing Function Definition
hashing functions are functions that map input data of some arbitrary size to fixed-size output values
Git uses an algorithm called SHA-1.
All commit hashes are 40 digit long hexadecimal numbers.
Git is a Key-Value Datastore
we give it data
it hands us back a key
we use that key to later retrieve that content
its like a coat check
but for data
You can manually hash, store, and retrieve anything using git commands without influencing a repo.
Ref Log
Git Reflog allows you to interact with the movement history of each reference (branches, HEAD, etc.)
The reflog remembers every commit that every reference pointed to along with the timestamp, for the last 90 days.
This allows you to forcibly move HEAD onto commits that have been deleted from the timeline.
You can use a hard reset to forcibly move a branch pointer onto a commit that’s in the trash using the reflog. Since each commit has a parent commit, you will essentially be dragging the whole chain out of the trash (and throwing away whatever used to be there).
Rebase and Reflog are both very powerful
Aliases
The global git config file is in the home directory of your computer. Surprise!
~/.config/git/config
You can create git command aliases in this file (or the local config files in each repo’s .git)
There are many blogposts about fancy and preferred git aliases. Usually pretty formatting for git log and such.
Commands – Other Parts
git switch feature
Switch to feature branch
git rebase master
Rebase current branch (feature) onto master
git rebase –abort
After a conflict is found, choose to abort the rebase operation
git add
After manually resolving conflicts, re-add the files for the previously failed commit
git rebase –continue
After manually resolving conflicts and re-adding, continue the rebase process of recreating commits
git rebase -i HEAD~4
Enter interactive rebase mode, addressing all commits between now and HEAD~4
git tag
Lists all the tags in the repo
git tag -l “<query>”
Search for specific names in tags
git tag <tagname>
Will create a tag of tagname on the commit HEAD is currently pointed to
git tag -a <tagname>
Creates an annotated tag
git show <tagname>
Reveals the metadeta for a specified annotated tag
git tag <tagname> <commit>
Create a tag for a previous commit by referencing its hash
git tag -f <tagname> <commit>
Forcibly move a tagname onto a different commit hash
git tag -d <tagname>
Delete a tag
git push <remote> –tags
Push all tags onto a specified remote
git push <remote> <tagname>
Push a single tag onto a specified remote
git hash-object <file>
Run SHA-1 with the file data as an input to generate a 40 hex hash
git cat-file -p <object-hash>
Retrieve a file associated with a given hash
git reflog show
Show the reflog for the current branch pointer/HEAD
git reflog show HEAD
Show the reflog for HEAD. Every location since the beginning of the repo
git reflog show <branchname>
Show the reflog for a given branch
git reflog show HEAD~4
Show the reflog up until the commit 4 commits ago on the CURRENT BRANCH
git reflog show HEAD@{10}
Show the complete reflog for HEAD up until wherever HEAD was pointing 10 jumps ago (can move between branches)
Command Sheet
Commands – Git Core
git status
check the status of the repo you are in
git init
create a repo inside the current directory
git add <file>
this is how you move files into the staging area when preparing for a commit
git add .
this is how you quickly add all files to the staging area
git commit -m “commit message”
this is how you create a savepoint on the timeline. it takes all the recently changed files that have been “add”ed to the staging area and takes a snapshot you can refer to and return to. commits require commit messages, preferably written in present imperative tense
git log
prints a list of all the commits in a repo
git log –oneline
more condensed version of git log
git config –global core.editor “code –wait”
Sets global config to use VSCode as your text editor for git functions
git commit –amend
Lets you add files that were forgotten to the most recent commit
git branch
lists all branches in the repo. active branch will be * marked
git branch <branch-name>
creates a new branch. Does not switch you to it. no spaces in branch names.
git switch <branch-name>
Switch branches
git checkout <branch-name>
exact same functionality of git switch. more old school.
git switch -c <branch-name>
Create a new branch, and switch to it.
git checkout -b <branch-name>
Create a new branch, and switch to it. more old school.
git switch -d <branch-name>
Deletes the branch. You can’t delete the branch you’re on. (should be merged)
git switch -D <branch-name>
Forcefully deletes a branch.
git branch -m <new-name>
Renames the branch you’re currently on. You can target another branch as well.
git merge <branch-name>
Merge the specified branch into the active branch
Commands – Next Level Git
git diff file1 file2
Render the differences between the two files
git diff
Will show unstaged changes vs. HEAD
git diff HEAD
Will show staged changes vs. HEAD
git diff –staged
Will show ONLY staged changes vs. HEAD
git diff HEAD file
Will show only the changes vs. HEAD for a specific file
git diff branch1..branch2
Will diff every single file between two branches
git diff commit1..commit2
Will diff every single file between two commits (commits are referenced via hashes)
git stash
Reverts your working directory back to match the last commit/HEAD
git stash pop
Replaces the current working directory with whatever was stashed before
git stash apply
Applies the stashed changes to the current HEAD, even if on a different branch. Does not clear the stash.
git stash list
Lists all the stashed sets of changes
git stash drop stash@{2}
Deletes the stash from two stashes ago
git stash clear
Deletes all stashed changes
git checkout HEAD~1
Will checkout whatever commit came immediately before the current one
git switch –
Will reattach head by switching to whatever branch you were on before detaching
git checkout HEAD <filename>
A quick way to revert a file to base after making changes
git checkout — <filename>
Same function
git restore <filename>
Reverts file back to last commit (Same Function)
git restore –source HEAD~1 <filename>
Reverts file to whatever it was the commit before last
git restore –staged <filename>
Removes file from staging area (un-adds)
git restore –staged .
Clears entire staging area.
git reset HEAD~1
Deletes most recent commit and moves repo back one. Retains file changes
git reset –hard HEAD~1
Deletes both commit and changes. Reverts repo back one commit.
Commands – Collab Core
git clone <url>
Downloads and inits a local copy of the repo referenced in the url
git remote -v
Lists the remotes/destinations the repo knows about
git remote add <name> <url>
Adds a remote destination for pushing and pulling associated with name and url
git remote rename <old> <new>
Rename a remote
git remote remove <name>
Remove a remote
git push <remote> <branch>
Pushes a branch’s local commit history onto the remote repo
git push <remote> <local-branch>:<remote-branch>
Push a particular local branch onto a particular remote branch
git push -u <remote> <branch>
Push a local branch to a remote, and set the default destination for that local branch
git branch -r
Will list the remote tracking branches in the repo
git switch <remote-branch-name>
Creates a local branch matching the name of a remote branch and sets up tracking
Commands – Other Parts
git switch feature
Switch to feature branch
git rebase master
Rebase current branch (feature) onto master
git rebase –abort
After a conflict is found, choose to abort the rebase operation
git add
After manually resolving conflicts, re-add the files for the previously failed commit
git rebase –continue
After manually resolving conflicts and re-adding, continue the rebase process of recreating commits
git rebase -i HEAD~4
Enter interactive rebase mode, addressing all commits between now and HEAD~4
git tag
Lists all the tags in the repo
git tag -l “<query>”
Search for specific names in tags
git tag <tagname>
Will create a tag of tagname on the commit HEAD is currently pointed to
git tag -a <tagname>
Creates an annotated tag
git show <tagname>
Reveals the metadeta for a specified annotated tag
git tag <tagname> <commit>
Create a tag for a previous commit by referencing its hash
git tag -f <tagname> <commit>
Forcibly move a tagname onto a different commit hash
git tag -d <tagname>
Delete a tag
git push <remote> –tags
Push all tags onto a specified remote
git push <remote> <tagname>
Push a single tag onto a specified remote
git hash-object <file>
Run SHA-1 with the file data as an input to generate a 40 hex hash
git cat-file -p <object-hash>
Retrieve a file associated with a given hash
git reflog show
Show the reflog for the current branch pointer/HEAD
git reflog show HEAD
Show the reflog for HEAD. Every location since the beginning of the repo
git reflog show <branchname>
Show the reflog for a given branch
git reflog show HEAD~4
Show the reflog up until the commit 4 commits ago on the CURRENT BRANCH
git reflog show HEAD@{10}
Show the complete reflog for HEAD up until wherever HEAD was pointing 10 jumps ago (can move between branches)
Review
Git Core
1
Matrix of Topics
Git Core
2
Intro to Git
3
Installation
4
Git Basics
5
Committing In Detail
6
Branching
7
Merging
Next Level Git
8
Diffing
9
Stashing
10
Undoing Changes
Github/Collab Core
11
Github Intro
12
Fetching & Pulling
13
Github Odds & Ends
14
Collaborative Workflows
Git: The Other Parts
15
Rebasing
16
Interactive Rebasing
17
Git Tags
18
Git Behind The Scenes
19
Reflogs
20
Custom Alises
2
Git is the dominant version control software
Git is a software program that runs locally on your computer
Github, Gitbucket, and others are online platforms for uploading, sharing, and publicly maintaining codebases
3
You need to install Git
And then you need to configure it, by setting up a user account and such
There are GUI softwares that make Git easier to use so you’re not stuck in CLI the whole time
CLI – Command Line Interface
GitKraken
Git Commands
git config –global user.name “Tom Hanks”
git config –global user.email “tomhanks@gmail.com”
CLI Commands
CD
RM
LS
PWD
MKDIR
RMDIR
TOUCH <filename>
CLEAR
ls -a
list all, including hidden
rm -rf
remove, recursive, force.
4
Git takes a folder and makes it into a repository
A Repo is a git workspace
Do not initialize a repo when you are inside a repo!
If there is any doubt, run git status
If git status returns an error, you are not in a repo
There is a hidden .git folder in every repo. This contains all the file versions, timelines, histories, etc. of the git repo. Don’t touch it if you don’t know what you’re doing. and don’t delete it.
Three Locations
Working Directory
the directory you’re actually working in, changing files, moving stuff around, etc.
Staging Area
this is the holding area for files that are soon to be committed
Repository
this is there all the commits exist.
as you make more and more commits with new snapshots of the files from the working directory, the repo will expand with more history
a commit is a savepoint. the repo is the save folder
Workflow
The three areas
The actions that move files between these areas
Working Directory
>git add
Staging Area
>git commit
Repository
Commands
git status
check the status of the repo you are in
git init
create a repo inside the current directory
git add <file>
this is how you move files into the staging area when preparing for a commit
git add .
this is how you quickly add all files to the staging area
git commit -m “commit message”
this is how you create a savepoint on the timeline. it takes all the recently changed files that have been “add”ed to the staging area and takes a snapshot you can refer to and return to. commits require commit messages, preferably written in present imperative tense
git log
prints a list of all the commits in a repo
git log –oneline
more condensed version of git log
5
If you check the docs, git commit has a billion options and flags.
You will go insane attempting to read the git docs fully
There is a Git Pro Book that is more sequential than the reference
An essential concept is “Atomic Commits”
Each commit should be focused on a single thing, a single change
Commits should be indivisible into smaller changes
It makes it easier to navigate timelines and rollback changes to a specific point
It also simplifies the commit messages
Official git documentation states to use Present Tense Imperative Mood
Git needs a text/code editor that it’s allowed to open for specific functions
If you run git commit without the -m, it’ll want to open the code editor
Only in advanced and complicated projects will you need to write long commit messages
Git log –oneline is one of the most useful commands.
Sometimes you want the hash codes associated with each commit
GUI Tools like GitKraken can open several repos like tabs in a web browser
The Diagrams the GUI tools make for branching and merging are very useful
If you finish a commit and realize you forgot a file, you can add it to the staging area and rerun commit with the –amend flag to sneak it in to the most recent commit only. You will also have an opportunity to edit the commit message
example
git commit -m ‘some commit’
git add forgotten_file
git commit –amend
The .git folder contains a .gitignore file.
Three formatting options for flagging files to be ignored
.DS_Store
will ignore files named .DS_Store
folderName/
adding the / at the end will ignore an entire directory
*.log
will ignore all files with .log extension
Virtually every github repo will have a .gitignore.
There are useful tools like gitignore.io that can actually generate recommend .gitignore file contents depending on the environment you’re working in like Python, JS, etc.
Commands
git config –global core.editor “code –wait”
Sets global config to use VSCode as your text editor for git functions
git commit –amend
Lets you add files that were forgotten to the most recent commit
6
Every commit has a hash
Every commit also contains a reference to at least one parent commit, via the parent’s hash
The initial commit that creates the repo is the only commit that doesn’t have a parent
Git has branches, so commits can be added to the same repo on different timelines
Without branches, software development would have to be perfectly linear, and developers could not meaningfully collaborate, nor work in parallel.
The Master Branch is now being renamed to Main branch by github for social reasons
There’s nothing special about these branches in particular
Standard practice is to treat the master branch as the official branch
Git has a HEAD.
(HEAD -> master)
The HEAD is a pointer that references the current Branch
Specifically, each branch has a Branch Reference, which is also a pointer
The Branch Reference pointer points to a particular commit by its hash
The HEAD then points to the branch reference pointer.
So there’s a pointer pointing to a pointer pointing to a hash
So there’s a HEAD pointing to a BRANCH REFERENCE pointing to a COMMIT
The HEAD can be made to point directly to a commit.
If the HEAD is not pointing at a Branch Reference, it is said to be DETACHED
If the HEAD is pointing directly at a commit hash, it is DETACHED.
If you create a new branch, and do nothing else
Both the master branch and the new branch will have distinct branch reference pointers
But they will be pointing at the same commit.
From that point on, it matters which branch you have active when you commit, as you will be traveling along different forks in the road
When you switch branches, you are pointing your HEAD at a different branch reference
The HEAD is whatever commit on whatever branch you have open currently.
The HEAD is akin to whatever page of the book you have open. The branch pointers are akin to bookmarks at different points in the book. You can only have one page of the book open at a time. Whatever page is open, that’s where the HEAD is.
If two branches are still pointing at the same commit, and that’s also where HEAD is pointing, then git log will list both of them
(HEAD -> master, pbj)
Git log will return different results based on each branch
Each branch has a unique log & perspective
Git log is a serialized list of commits that culminate in the most recent commit of the active branch
It does matter where you branch from. This should be obvious.
Git checkout used to do everything. They made new commands so it wouldn’t have to.
Also, it was confusing
If you have unstaged changes on a particular branch and then try to switch to a different branch, it will warn you that the act of switching branches will overwrite and delete your uncommitted changes.
$ git switch pbj
error: Your local changes to the following files would be overwritten by checkout:
playlist.txt
Please commit your changes or stash them before you switch branches.
Aborting
Your options are to finish the commit, or to use git stash.
You can do this intentionally to reset the working directory and clean the whiteboard
When you delete a branch, you have two options, -d, and -D
-d only works if the branch has been merged into an upstream branch. This is more of a cleanup procedure
-D is force delete. It will find the origin point of the branch and delete the entire history of commits associated with that branch
The .git folder contains a HEAD file and a /refs folder
the /refs folder contains further folders named after each branch.
These branch folders contain a single file that contains the hash of the commit the branch reference is pointing to
The HEAD file contains the address of the branch reference file.
The HEAD file can contain instead an explicit hash rather than a subdirectory address. This is the detached HEAD condition.
Commands
git branch
lists all branches in the repo. active branch will be * marked
git branch <branch-name>
creates a new branch. Does not switch you to it. no spaces in branch names.
git switch <branch-name>
Switch branches
git checkout <branch-name>
exact same functionality of git switch. more old school.
git switch -c <branch-name>
Create a new branch, and switch to it.
git checkout -b <branch-name>
Create a new branch, and switch to it. more old school.
git switch -d <branch-name>
Deletes the branch. You can’t delete the branch you’re on. (should be merged)
git switch -D <branch-name>
Forcefully deletes a branch.
git branch -m <new-name>
Renames the branch you’re currently on. You can target another branch as well.
7
1. You merge branches, not commits
2. You merge the specified branch into the active branch
Workflow
git switch master
git merge bugfix
If master hasn’t changed at all since the branchpoint for the feature branch
Then merging the feature branch into master will consist only of appending the feature branch’s commits onto master.
No conflicts are possible, because master hasn’t changed since the feature branch was created.
This scenario is called a fast-forward merge
After a merge, the branch does not go away. They can fork again.
Merges are easy to visualize using GitKraken or some other GUI tool
When merging, there’s a chance git won’t be able to perform the merge automatically.
Either due to conflicting information or if both branches contain novel data
Git will create a modified version of the file that has both versions of the data, the one from the extant branch, and the one from the absorbed branch
in a format like this
HEAD<<<<<<<<<<< head content ========== branch1 content >>>>>>>>>branch1
Given the material from both, you can choose to keep one or the other, mix and match, or write something new to get them to cooperate.
Once you remove the conflict markers and save the document, you can add your changes and commit.
The active branch receiving the merge will generate a new commit in the process, known as a merge commit. It has it’s own commit message like normal
git merge branch2 -m “mergecommit message” is an example
You can use the -m flag on it
These merge commits have two parent commits instead of one.
When you delete a branch, it will warn you that all the changes contained within that branch haven’t been merged into master, unless they have
Commands
git merge <branch-name>
Merge the specified branch into the active branch
Next Level Git
8
Git diff is useful for reviewing the differences between specific commits, files, branches, etc.
git diff, git log, and git status are all useful to understanding the state and history of the repo.
None of these commands have any effect on the repo.
Git diff will actually print out a bunch of text lines, labeled with the line number ranges, of the changes you made,
and mark the removed lines with — flags
and mark the new content with ++ flags
and even color them red and green
If you git diff in a repo with multiple files that have been changed, it will list off a git diff for each file
Syntax of Chunk Headers
the code chunk line number range things are broken down like this
@@ -3, 4 +3, 5 @@
notice the lack of comma after 4
what it’s saying is
from “-” which refers to file a
line 3
and then four lines after that
from “+” which refers to file b
line 3
and then five lines after that
this is called a CHUNK HEADER
git diff HEAD will show staged changes vs. last commit (HEAD)
git diff will show unstaged changes vs. last commit (HEAD)
GUI tools are great for viewing diffs
Commands
git diff file1 file2
Render the differences between the two files
git diff
Will show unstaged changes vs. HEAD
git diff HEAD
Will show staged changes vs. HEAD
git diff –staged
Will show ONLY staged changes vs. HEAD
git diff HEAD file
Will show only the changes vs. HEAD for a specific file
git diff branch1..branch2
Will diff every single file between two branches
git diff commit1..commit2
Will diff every single file between two commits (commits are referenced via hashes)
9
Some people simply do not use git stash
If you make changes to a branch, don’t commit them, and then try to switch to a different branch
1. the changes go with you to the new branch
2. git finds a conflict and won’t let you switch
The way around both of these scenarios is to stash.
Any time you need to switch branches before you’re ready to commit the stuff you’re working on
Most people just use git stash and git stash pop
But you can also pull out the stashed changes on a different branch somewhere else
Commands
git stash
Reverts your working directory back to match the last commit/HEAD
git stash pop
Replaces the current working directory with whatever was stashed before
git stash apply
Applies the stashed changes to the current HEAD, even if on a different branch. Does not clear the stash.
git stash list
Lists all the stashed sets of changes
git stash drop stash@{2}
Deletes the stash from two stashes ago
git stash clear
Deletes all stashed changes
10
Git Checkout is a swiss army knife.
The Docs will show this
You can git checkout <hash> a particular commit and enter detached HEAD
While in detached HEAD you can look around, make experimental changes, make and discard commits, etc. without impacting any other branches
You leave detached HEAD by switching to any branch
This makes sense, because HEAD is supposed to be pointing at a branch anyway.
When you git checkout the hash of an old commit,
You’ll find that git status and git log will show that the checked out commit is the most recent commit in the timeline.
detached HEAD is a form of time travel, back to when that commit was the most recent commit.
When in detached head, you can do 3 things
1. stay in detached head, examine, poke around, etc.
2. leave and go back via git switch, canceling changes
3. create a new branch from this point and switch to it
Changes deleted when you reattach the HEAD by switching to a branch, unless you do #3. In which case your changes will be retained, as you created a new branch.
This is how you time travel backwards to take a new path forward.
Git switch and git restore were both introduced to get away from using git checkout for everything
Git restore discards changes on a particular file and reverts it back to last commit. This command is not undoable. You cannot get the discarded changes back.
You can also use git restore to unstage files, if you decide not to commit them.
Git reset is how you rewind the timeline. Revert the entire repo back to a particular commit hash
It will delete everything past that point in time
It doesn’t revert the files and their changes though. It only affects the commit history
So you’ll delete all the commit messages and instances, but keep all the code changes
if you’re absolutely sure you want to delete both the commits AND the file changes, use hard reset
>git reset –hard HEAD~1
If there is a branch forked off of a commit sometime after the commit you’re hard resetting to, it won’t get deleted
There’s no reason for the BRANCH2 to have to forget everything, it has it’s own version of the history independent of whatever resets occur elsewhere
Git revert targets a commit hash, and creates a new commit & message with a set of files that do not contain the changes in the targeted commit.
So it basically creates a new commit that is a clone of the commit before the one specified
This lets you create a new fork in the timeline at some previous point without cutting off parts of the timeline.
This is important because you never want to delete commits that other people have access to.
It’s pretty much always better to add new instances than to cut off, scrub, or delete commit histories – and it’s essentially mandatory when collaborating with others
Commands
git checkout HEAD~1
Will checkout whatever commit came immediately before the current one
git switch –
Will reattach head by switching to whatever branch you were on before detaching
git checkout HEAD <filename>
A quick way to revert a file to base after making changes
git checkout — <filename>
Same function
git restore <filename>
Reverts file back to last commit (Same Function)
git restore –source HEAD~1 <filename>
Reverts file to whatever it was the commit before last
git restore –staged <filename>
Removes file from staging area (un-adds)
git restore –staged .
Clears entire staging area.
git reset HEAD~1
Deletes most recent commit and moves repo back one. Retains file changes
git reset –hard HEAD~1
Deletes both commit and changes. Reverts repo back one commit.
GitHub/Collab Core
11
Github
Started in 2008
56M devs, 100M repos
Largest Code Base Host in the world
The primary home for all open source projects
Making Open Source Contributions is a great way to prove you know what you’re doing. Proof of work
Git clone is a git thing, not a github thing. You can git clone from the other hosts like GitLab, etc.
You can’t just push changes up to a repo you don’t own. There are protocols for this. You can clone whatever you want though.
If you want your local git install to associate with your github account, you have to do some authenticator nonsense.
Basically
1. generate an SSH key
2. tell github about it
But it looks like they recently changed the auth process so it’s probably always a pain
The way you use github is to publish an existing repo on your local machine, up onto the public web
Workflow
0. Authenticate git & github
1. Create a new repo on local machine
2. Create a repo on github
3. Add the github repo as a “remote”
4. Push repo up to github
You can also
1. Create empty repo on github
2. Clone down onto local machine
3. Make changes and push back up
Git repos have remotes. Remotes are instances of the repo that are not local to the machine.
Each remote is just a URL.
Remotes can be destinations for pushing local code onto
Or they can be sources to pull code from onto local
They’re usually both, not just one or the other
When you create a new repo on github, it’ll tell you how to push to it from command line
…or push an existing repository from the command line
git remote add origin https://github.com/fishPointer/psychic-octo-rotary-phone.git
git branch -M main
git push -u origin main
The first line adds the remote pointing to your repo
The second line renames the master branch to main, optional
The third line pushes the local commit history for the “main” branch up to the remote named “origin”
You don’t push commits. You push entire branches.
In practice, you might be pushing the whole branch every commit though.
You don’t necessarily want to push all branches at once, and you don’t necessarily want to push the branch you’re currently on
Github has a strong UI for viewing branches, commit history, comments, etc.
Basic push workflow
make changes
>git add .
>git commit -m “message”
push up to github
>git push origin master
There’s a distinction between the branches you have locally and the branches you have on github
There are two “master”s, one local, and one remote
>git push <remote> <local-branch>:<remote-branch>
In order to specify which local branch should be pushed to which remote branch
Meaning you don’t just have to push master to master every time. You can push branch2(local) onto master(remote)
You can use -u flag when pushing to set a default remote and remote branch for a particular local branch.
That way you can just use “git push” next time you want to push that branch
git push -u origin master
The upstream desgination -u is per branch
The reason to make an empty repo on github and then clone it onto your machine is that you can skip the step of setting up the remote
Github’s recommended commands include a rename line for main
>git branch -M main
Commands
git clone <url>
Downloads and inits a local copy of the repo referenced in the url
git remote -v
Lists the remotes/destinations the repo knows about
git remote add <name> <url>
Adds a remote destination for pushing and pulling associated with name and url
git remote rename <old> <new>
Rename a remote
git remote remove <name>
Remove a remote
git push <remote> <branch>
Pushes a branch’s local commit history onto the remote repo
git push <remote> <local-branch>:<remote-branch>
Push a particular local branch onto a particular remote branch
git push -u <remote> <branch>
Push a local branch to a remote, and set the default destination for that local branch
12
Remote Tracking Branches
Git Fetch
Git Pull
Since a branch is just a pointer that points to a particular commit
When you clone a repo from online, there are two pointers for each branch
The local one, which gets updated every time you make a local commit
And the remote tracking branch pointer, which does not change, and is frozen in time whenever you last pulled data from the remote
“At the time you last communicated with this remote repository, here is where branch X was pointing”
that’s the information contained by the Remote Tracking Branch
Remote tracking branch nomenclature: <remote>/<branch>
>git branch -r
The -r flag shows the remote branches automatically detected from when you cloned/pulled last
Once those two references diverge because you added a new commit
>git status will tell you
“Your branch is 1 commit ahead of origin/main by 1 commit”
To indicate you have moved on from the remote tracking branch
Once you push, you’ll have interacted with the remote, and the remote tracking branch pointer will point to the newest commit on the branch you pushed.
When you first clone a repo, you won’t see all the branches with git branch
But if you run it with -r you’ll see all the remote branches in the repo
When you clone the repo, there’s automatically a connection between local/master and origin/master
But if you want to work on other branches, that connection needs to be made manually
The newer git switch command has this functionality built in already
>git switch <remote-branch-name>
creates a new local branch with matching name
AND
sets it up to track the remote branch origin/<name>
does both
Git Fetch and Git Pull are different
Fetch will clone the most recent version of the remote repo into the LOCAL REPO
Pull will clone the most recent version of the remote repo into the WORKING DIRECTORY
Meaning when you Pull, you lose your work
When you git clone, origin/master does not update dynamically with everything else going on in the world. git is not always online like that
That’s what git fetch is for though. You can ping the directory and download all the most recent changes while you continue working on whatever you’re working on
If the remote repo has had 100 new commits since you pulled/fetched, and you run git status, it will tell you you’re up to date. Because git status references the screenshot of the online repo at the last moment you interacted with it.
Pull will move your HEAD
Fetch will not move your HEAD
Pull is basically a combo of fetch and merge.
Where you are when you Pull matters, since the active branch is the one that’s going to get merged into by remote content
Git pull can and will result in merge conflicts
Because your version has changes that will conflict with the recent updates
Pull is more dangerous than fetch
Summary
Fetch
gets changes from remote branches
updates the remote-tracking branches with new changes
Does not merge changes onto your current HEAD branch
Safe to do at any time
Pull
gets changes from remote branches
updates the current branch with the new changes, merging them in
Can result in merge conflicts
Not recommended if you have uncommitted changes
Commands
git branch -r
Will list the remote tracking branches in the repo
git switch <remote-branch-name>
Creates a local branch matching the name of a remote branch and sets up tracking
13
Github repos can be public or private
Private repos are whitelisted, only visible to a few
Common practice is to start private, go public later
Collaborators must be invited manually, and they must accept. Mutual agreement.
Every Github repo is going to have a README.md. README has to be in all caps.
Github will automatically detect and render the README as the blogpost beneath the list of files when you view the homepage of a repo
.md is for markdown, a succinct and convenient syntax for generating formatted text
Markdown is a tool that generates markup
Text-to-HTML conversion tool
Advertised as easy to read and easy to write
https://markdown-it.github.io/
^^ contains a more perfect reference of all the formatting features than I could write up as the default file
Most of the time when you’re working on a project you don’t really expect anybody to ever see it
Recruiters are almost definitely only going to look at the README. Non-technical people will not look at your code
You have to add and commit and push the README just the same as you would any other file
Make sure you make pretty README files and have a good grasp on Markdown
Gists
A simple way to share snippets of code
Like Pastebin
Lightweight version of the repo
No commits and pushes and stuff
Just a very fast way to share code
Sometimes a gist is more appropriate
Github Pages
Pages hosted and published out of GitHub repos via GitHub
You can make a website easily
Static webpages only
No serverside stuff
Clientside only, just HTML/CSS/JS
You get one user site
You might use username to host a portfolio or personal website
Project sites are unlimited, one for each repo
You can have a perfectly normal project
And then make a branch where you made a GitHub page
You select a branch in the repo
And tell GitHub it has a website for GitHub Pages
Specifically an index.html file
14
Centralized Workflows – everyone works on the same master branch
Without any other branches, two people will invariably work on new changes from the same commit, and then conflict with eachother.
Once the first pushes, the second cannot push, because their local repo’s commit history does not match the remote repo’s commit history. They have to fetch/pull before they can commit. And this process can and will create conflicts as well.
There’s also no way to share code with your collaborators to review without publishing half-baked code directly onto master and breaking it.
And then the person who wants to review that broken code has to stash their own WIP changes in order to fetch yours.
Collaboration options are very limited.
The Feature-Branch Workflow is the universal solution and the main collaboration pattern for this stuff.
Treat the master branch as the all-important – never to be touched branch
It acts as the official project history.
All new work is done on separate feature branches, which are then merged into the master branch upon completion and team approval
No new work is done directly on the master branch
Now multiple teammates can collaborate on a single feature and share code without corrupting the master branch
Managed properly, the master branch will never contain broken code
Branches are feature-oriented, not person-oriented
So it’s not like “David’s branch” and “Pamela’s branch”
The branches are per feature, regardless of who is responsible for it, or how many people work on it
People in large corporations have nomenclature and protocols for creating feature branches
There will be thousands and thousands of feature branches
But not all of them show up on GitHub, because they don’t need to
Once they’re merged into master, they’re usually deleted to keep the public work on the repo clean
Magic Workflow: How to merge a feature branch without pushing it to GitHub
Pull the latest changes from remote master
Create a local feature branch
Build out the feature, make some commits
Switch to master
Pull the latest changes from remote master
Merge the feature branch into master
Resolve conflicts if any
Push master up to remote
Delete any local or remote instances of the feature branch
Obviously someone will be in charge of deciding who gets to merge what into master and when. Anarchy is the alternative
Pull Requests are the social mechanism by which we submit changes for approval.
“i have new stuff i want to merge into master. what do you think?”
There are also ways to explicitly protect the master branch so it can’t be modified without approval
If the master branch isn’t protected, then the person submitting the PR can choose to just bypass that procedure and click merge anyway
Workflow
Do work locally on feature branch
Push feature branch to github
Open a pull request to the feature branch you just uploaded
Wait for the PR to be approved and merged. start a discussion. team structure stuff. etc.
The PR has a name
It has the master branch, and the branch requesting to merge
You can write a description of what the change is and why, including file attachments, etc.
Once you make the pull request, the boss is the one who approved it and hits the merge button
There’s a lot of structure and formatting and nomenclature concern for submitting proper pull requests to open source projects
There are often a lot of pull requests on these projects and it may take a while to get things reviewed
Also, the PRs effectively act as forum threads or discussion posts
Sometimes there are conflicts, of course
The PR will notify you that there are conflicts, and there’s a button to resolve conflicts
Sometimes it’s simple enough that you can resolve the merge issue in the browser with the GitHub file editor
But realistically, if you have to address multiple issues across multiple files, it’s probably better to just start from the command line
GitHub will give you the command to handle these merge conflicts yourself
Step 1: From your project repo, bring in the changes and test
git fetch origin
git checkout -b new-heading origin/new-heading
git merge main
Step 2: Merge the changes and update on GitHub
git checkout main
git merge –no-ff new-heading
git push origin main
As a result of the fetch, you’ll have access to the new branch the other person (who made the PR) made and pushed up to GitHub
You need a local copy of their work in order to review it properly
From there, you can switch to the feature branch
And then merge in your local copy of the master branch
Note that this is the reverse of the previous process
Where we merged feature into master
Once we resolve the conflicts, we should be able to do it the other direction without conflict: merge feature into master
so yes, you merge feature <- master and then immediately after master <- feature
Workflow:
Acquire feature branch, resolve conflicts
git fetch origin
git switch feature
git merge master
Fix conflicts
Merge feature conflictless, push to GitHub
git switch master
git merge feature
git push origin master
After you do all this, and it’s pushed up and the PR is closed
Repos can be config’d with branch protection rules and the like
You can also define branch name patterns
The repo can enforce naming rules for large projects
If you clone someone else’s repo
You can’t make changes and push it up to GitHub to show someone else
A fork is a personal copy of someone else’s repo on your own account
You’re not cloning the repo onto your machine; you’re cloning the repo into another repo that you control
Forking is not native to Git, but another GitHub quality-of-life feature
Instead of just one centralized GitHub repo, every developer has their own GitHub repo in addition to the “main” repo
Developers make changes and push to their own forks before making PRs
Common on large open-source projects
Thousands of contributors but only a few maintainers
So, like a supersystem above feature branches
This system enables anybody to make changes
They don’t need permission from the owners of the repo to become a contributor
Your fork will need two remotes. One for your personal fork, and one pointed at the original to pull novel changes from
His summary of the workflow:
1. Fork the project
2. Clone the project
3. Add upstream remote
4. Do some work
5. Push to origin
6. Open PR
You can open Pull Requests across Repos. That’s what makes this whole thing work.
You create a modified version of the repo on your personal fork, and then present those changes to the project owner.
Git: The Other Parts
15
Git rebase is controversial and many people avoid it
Engineering teams often prefer it
Primarily Used as either
1. An alternative to Merging
2. A Cleanup Tool
If you are working on a feature branch while master is getting updated, you will have to regularly pull new commits on master, and then merge them with your feature branch as you go.
This creates an ugly and unreadable commit history
Rebasing will recreate each commit in the feature branch one by one, and then graft the chain of commits onto the most recent commit in master.
This deletes all the merge commits along the way, and linearizes the commit history
Rebasing should never be done on a commit history that other people already have access to. You should only rebase work that is done locally, as a way of tidying it up before you share it.
Rebasing creates new commits with new commit hashes and deletes the old commits. This creates issues when you rebase code that is in shared history.
It’s called rebasing because you’re collecting all the feature branch commits and then moving their base to the most recent master branch commit
If you have pushed it before, don’t rebase it.
Because it manually recreates each commit from the feature branch at the tip of master
It’ll let you know which commit it fails at due to a conflict
You can resolve the conflict manually as you normally would and move forward, or just abort
Commands
git switch feature
Switch to feature branch
git rebase master
Rebase current branch (feature) onto master
git rebase –abort
After a conflict is found, choose to abort the rebase operation
git add
After manually resolving conflicts, re-add the files for the previously failed commit
git rebase –continue
After manually resolving conflicts and re-adding, continue the rebase process of recreating commits
16
Rebase has an interactive mode where you can tweak commits in detail
You can reword, fix up, edit, and drop commits individually
This is the cleanup tool functionality
git rebase -i HEAD~4
The -i flag enters interactive rebase mode
The HEAD~4 indicates we’re recreating the last 4 commits on this branch, where the HEAD is currently
Since you’re in interactive mode, you can change the name of a commit as it’s recreated, or just choose to drop it and not recreate it
It’ll open the text editor and each commit in the commit history will be associated with a function word
List of Function Words
pick
use the commit
reword
use the commit, but edit the commit message
edit
use the commit, but take a moment to amend the commit
fixup
use commit contents, but combine it with previous commit and discard this one’s commit message
drop
remove commit from history
Note that with fixup and drop you can change the total number of commits.
It’s a good practice to create a new branch and switch to it before doing the rebase, so you can keep a copy of the non-rebased work just in case.
Commands
git rebase -i HEAD~4
Enter interactive rebase mode, addressing all commits between now and HEAD~4
17
Git tags are not difficult and uncommonly used
They are de facto only used for Semantic Versioning
A tag is just another pointer, like the branch reference, but it points to a single commit and never changes. Just a label for a for a particular commit.
The only occasion you would want to tag something is when a new version is creates as a result of merging a feature branch into the master branch. That merge commit is likely to have a tag.
That tag is also likely to have a name like “v3.1.0”
There are two types of tags
Lightweight Tags
Simple
Annotated Tags
Contain metadeta: tag name, user name, pusher name, timestamp, tag message
It’s important to understand proper versioning as well.
Semantic Versioning
Semantic Versioning is a software standard, like a benchmark that software can be observed to comply with. There’s a defining document and all that.
Semantic Versioning consists of three numbers: v1.2.3
1 is the major release.
2 is the minor release.
3 is the patch.
For patch changes, the alterations should be small and should not disturb or break existing functionality.
The minor releases will include new features and moderate changes but still retain backward compatibility.
The major releases are where significant changes are made, features might be removed, and backward compatibility is broken.
The 1.0.0 version is when the official, public-facing API is defined. So, if there’s not a complete public release that non-developers can be expected to use, it’s not 1.0.0 yet.
They either start with “v” or they don’t. Make sure you’re consistent!
Searching Tags
git tag -l “*beta*”
the * is a wildcard, so any character or number of characters
and so you’re looking for all tags with beta in it at any point
*beta would imply that you want it at the end
beta* would impy you want it at the beginning
the -l flag is necessary for this searching function
so searching like “17” will get you nowhere
but “v17*” will get you all the v17 releases
You can git checkout by tag name as well as git diff. You’ll still go into detached HEAD. This should be obvious.
Git will not let you reuse a tag and point the same tag name at another commit
In order to force it to move the tag to a different commit, we use the -f flag
When you push your local repo up to GitHub
By default, tags are not going to be included
Commands
git tag
Lists all the tags in the repo
git tag -l “<query>”
Search for specific names in tags
git tag <tagname>
Will create a tag of tagname on the commit HEAD is currently pointed to
git tag -a <tagname>
Creates an annotated tag
git show <tagname>
Reveals the metadeta for a specified annotated tag
git tag <tagname> <commit>
Create a tag for a previous commit by referencing its hash
git tag -f <tagname> <commit>
Forcibly move a tagname onto a different commit hash
git tag -d <tagname>
Delete a tag
git push <remote> –tags
Push all tags onto a specified remote
git push <remote> <tagname>
Push a single tag onto a specified remote
18
Contents of .git
Objects folder
Contains the meat of the git repo. All the file versions from every commit are stored here
They’re stored in BLOBS – Binary Large Objects
There are 4 main types of git objects
commit
tree
blob
annotated tag
They’re all encryped by SHA-1. This is how the hashes are generated
All the data is stored here. Everything outside the objects folder is just an elaborate network of pointers.
The objects folder will contain subfolders named after the first two characters of each hash. If two objects have the same first two characters, you’ll find them in the same folder.
Refs folder
Branch pointers, tags, etc. are all stored and exist inside refs
refs/heads is another subfolder, containing a file for every branch in the repo
These files contain just the commit hash of the commit they point to. They are the branch pointers
There are also subfolders for remotes and tags
config file
index file
HEAD file
In the .git folder
Points to the subdirectory address of a particular branch pointer file in refs/heads
Something like this:
ref: refs/heads/master
Otherwise, it may contain a commit hash, which indicates detached HEAD
Config is set at three levels
system wide
globally
per-repo
Hashing Function Review
All commit hashes are 40 digits long – hex numbers
Hashing Function Definition
hashing functions are functions that map input data of some arbitrary size to fixed-size output values
Cryptographic Hash Functions are a subset of hash functions that have these characteristics
One-way function which is infeasible to invert
Small change in input yields large change in the output
Deterministic – same input yields same output
Unlikely to find 2 outputs with the same value
There are a few popular hashing functions that people use. SHA-1 is the one Git uses. It always produces 40-digit hex values. However, it’s a bit outdated, and there’s a desire to migrate to a new hash function. The process of migration is uncertain, and they haven’t determined how or when they’ll do that.
Key-Value Datastore
git is a key value datastore
we give it data
it hands us back a key
we use that key to later retrieve that content
its like a coat check
but for data
It doesn’t reverse the Hash. It just checks if the hash exists and points you back to the original
Manual Hashing
you can just manually hash random shit using git
git hash-object <file>
and it’ll run SHA-1 on it
you can run git hash-object anywhere, not just in a repo
just as you can run git init anywhere
because your machine knows git
Manual Retrieval
git cat-file -p <object-hash>
the -p is for pretty print
so the cat-file is the command, and when you give it the object hash
Keep in mind if you’re doing these manual hash commands and stuff, you’re not making any commits, just updating objects in the objects folder
`git log` will return nothing
The objects folder will store every version of every file
Albeit in an encrypted and compressed version
So as long as you don’t delete the .git folder, everything will be retained
Commands
git hash-object <file>
Run SHA-1 with the file data as an input to generate a 40 hex hash
git cat-file -p <object-hash>
Retrieve a file associated with a given hash
19
reflog can be used to get yourself out of sticky situations.
It’s for recovering deleted or lost commits
The tips and HEADS of branches change from time to time
The complete history of which commits they referred to, and the times at which they changed, are all kept in the ref log.
It logs the changes of the refs
Reflogs are local only, and the logs only track movements from the last 90 days
If you switch back and forth between branches, you’re moving HEAD between commits, and adding a bunch of entries to the reflog
You can used time-based specifiers like
git reflog master@{one.week.ago}
also
1.day.ago
3.minutes.ago
yesterday
Fri, 12 Feb 2021 14:06:21 -0800
and so on
Even if you hard reset the repo and force-delete a bunch of commits
The HEAD was pointing at them at some point
So you can just as well go into the reflogs, find the commit hash of deleted commits, and then git checkout and review them in detached HEAD
If you do something like
git reset –hard master@{1}
You will force-move the tip of the given branch to be the commit specified
Reflog gives us the pointers we need to check out old discarded commits that are not part of our official commit history
When you hard reset a branch pointer onto a discarded commit, you are ripping the pointer out of its context, and slapping it onto a commit you found in the trash
However, each commit object also refers to its own parent commit
So by hard resetting onto a commit found in reflog that’s been discarded from the official commit history, you’re effectively dragging the whole chain of trashed commits out of the can and putting the branch reference onto its tip.
This disembodies the new work and functionally swaps it into the trash instead
So you kind of trade the new work for the old work
Both reflog and rebase are very powerful and can cause havoc
Commands
git reflog show
Show the reflog for the current branch pointer/HEAD
git reflog show HEAD
Show the reflog for HEAD. Every location since the beginning of the repo
git reflog show <branchname>
Show the reflog for a given branch
git reflog show HEAD~4
Show the reflog up until the commit 4 commits ago on the CURRENT BRANCH
git reflog show HEAD@{10}
Show the complete reflog for HEAD up until wherever HEAD was pointing 10 jumps ago (can move between branches)
20
The global git config file is in the home directory of your computer. Surprise!
~/.config/git/config
You just open the config file, local or global, and create an [alias] entry
[alias]
s = status
l = log
p = push
under [alias]
<custom alias name> = <stock command name>
Lots of blog posts and Reddit posts about people’s favorites
Some for formatting Git log with colors and fancy spacing and stuff
These are actually pretty sweet
Give additional functionality and save time
Useful, for log formatting at least
If you put an ! in a Git alias, that tells Git that it’s a shell script
So you can run shell scripts in the terminal in your Git aliases as well
So people can run commands like grep and cat and stuff
Contents
1
Course Orientation
Intro
The best time to learn git is yesterday
Git is more than just some new syntax
“Living Git. Breathing Git. Second Nature. Fundamental Part of your Workflow”
Become one with Git
Pet chickens for variable names
Course Curriculum
Matrix of Topics
Intro to Git
Merging
Fetching & Pulling
Git Tags
Installation
Diffing
Github Odds & Ends
Git Behind The Scenes
Git Basics
Stashing
Collaborative Workflows
Reflogs
Committing In Detail
Undoing Changes
Rebasing
Custom Alises
Branching
Github Intro
Interactive Rebasing
???
Color Code
Git Core
Next Level Git
Github/Collab Core
Git: The Other Parts
Exercises
It’s hard to write practice exercises for git
Exercises at the end of each section
Accessing the Slides & Diagrams
There will be a “What Really Matters In This Section” video at the beginning of every section
It will have the slides attached and provide an overview
Nice touch
2
Introducing…Git!
What Really Matters In This Section
What Exactly Is Git?
Git is THE VCS
VCS – Version Control System
Software that tracks and manages changes to files over time
Revisit earlier versions of files
Compare changes between version
Undo Changes,
etc,
Other VCS – Subversion, Mercurial
Git has 88.4% market share.
Runner up is Subversion around 16.6
They stopped doing surveys it was so dominant
Visualizing Git
Git helps us
Track changes across multiple files
Compare versions of a project
Time Travel back to old versions
Revert to a previous version
Collaborate and Share changes
Combine Changes
Git is basically just the savepoint system for coding
Writers also use Git for version control
You can track versions and changes over time ofc
You can make forks and branches
But you can also merge/combine independent branches?
Seems like there could be dependency issues. If the branches are not totally independent changes of eachother they could conflict.
A Quick History of Git
Linux made Linux and Git
Git in 2005 after frustrated with shitty paid VCS
“Global Information Tracker” – on a good day
Who Uses Git?
Stackshare.io
Tech-Adjacent Roles use git too
Designers use git
Some govt’s have started using Git to draft laws
government.github.com
collaborative textbook writing
managing versions of novels, screenplays, etc.
daily diaries, composers of symphonies, drafting theses, etc.
Git Vs. Github: What’s the Difference?
Git runs on your computer
it runs locally. no cloud, no internet, no account
Github is a web service
It takes Git Repos and hosts them in a cloud
And makes them easy to collaborate with
You have to start with Git before you can move onto Github
3
Installation & Setup
What Really Matters In This Section
Installing Git: Terminal Vs. GUIs
Git is primarily a Terminal Tool
Git has several popular GUIs
Github Desktop
SourceTree
Tower
GitKraken
Ungit
List of GUI’s straight from Git site
https://git-scm.com/downloads/guis
The ability to fully manipulate git in a terminal is expected.
GUI’s are useful but use a lot of magic and obfuscate what’s happening behind the scenes. This can create problems down the line
For a skilled user, Terminal is faster
and there are things you can only do on a terminal
Commands are universal, so no investment in a particular wrapper
Course covers both side by side
WINDOWS Git Installation
Git was created for UNIX. Not Windows.
Windows don’t have UNIX by default
Command Prompt is the Windows CLI
CLI – Command Line Interface
BASH is the default shell for Linux and Mac
Git BASH is what we install
It emulates BASH on windows.
You can actually ignore the Git part and just use it as BASH
~/Dropbox/Root/TreeSheets/Lab/FPGA Bootcamp/Git
I can finally use LS and CD on windows
Install VS Code as the default text editor for Git BASH
Picked up a course on mastering VS Code as well
MinTTY
Verify you have git with
>
git –version
MAC Git Installation
Skip
Configuring Your Git Name & Email
you configure your name and email as a user profile, but there’s no account or anything
however
this will be what is listed as your name when you do contribute to a public repo
set your username/email
>
git config –global user.name “Tom Hanks”
git config –global user.email “tomhanks@gmail.com”
check your username
>
git config –user.name
already set to fishPointer and iantralmer@gmail.com
Installing GitKraken (Our GUI)
GitKraken time
Installed
Terminal Crash Course: Introduction
some bash stuff
not relevant to git itself
skippable
CD
RM
LS
PWD
MKDIR
RMDIR
TOUCH <filename>
CLEAR
Terminal Crash Course: Navigation
Gonna watch these at 2x
mac has >open .
windows has >start
Open windows explorer at current directory
>
start .
Terminal Crash Course: Creating Files & Folders
touch creates new files
but it has a secondary use of updating the modified time of an existing file
bc i touched it
touch can make multiple folders at once. so can mkdir
try not to use _ underscores in folder names
Terminal Crash Course: Deleting Files & Folders
rm totally deletes the file
time for flags
rm -rf
the -r is for recursive
the -f is for force
so it forces a recursive delete on the target directory
this is how you delete an entire folder
you can instantly delete an entire folder of important files that may not be backed up
ls -a
-a makes it list all, including hidden stuff
4
The Very Basics of Git: Adding & Committing
What Really Matters In This Section
Most Essential Section in this course
What Is A Git Repo?
repo – repository
manually tell it in which directories to create repositories
a repo is a git workspace
Our First Commands: Git Init and Git Status
how to instantiate a new repo
git status
>
git status
if you run git status in a directory that does not have a repo, you will get a fatal error
there is no status, there is no repo
Initalize a repo inside the current directory
>
git init
Once you initialize the repo, you can run >git status and not get an error
The Mysterious .Git Folder
once you init, nothing changes.
Where is the “git” in this folder?
There is actually a hidden folder
You can see it with >ls -a
Git Documentation:
https://git-scm.com/doc
Reference Manual:
https://git-scm.com/docs
docs are thorough and arcane
rule about hidden folders and hidden files
they all start with .
ls -a reveals .git
the .git folder contains all of the git stuff. the version history and such
you can actually >rm -rf .git and delete the .git folder
if you do that and run git status after, it’ll return an error
because you deleted the thing that made it a repo
now you have to git init again to remake the repo
it’s hidden so you don’t screw with it. you can delete EVERYTHING
not just this one. ALL TIMELINES
the entire spiderverse
A Common Early Git Mistake
Git tracks a directory and all nested subdirectories
you can test this by initializing a repo in an empty folder
then mkdir a new folder
and then enter the child folder and run git status
you are still in that same repo
the repo is going to contain everything within the directory it was initialized in as though it were the root of all things.
YOU DO NOT WANT TO INIT A REPO INSIDE OF AN EXISTING REPOSITORY
git will git confused when git is asked to track gitself
you don’t want to make a repo in like, My Documents, or Desktop
It’ll end up tracking –everything– and that’s not really how people usually use git
The Committing Workflow Overview
commit time
bread and butter
Workflow
Working Directory
>git add
Staging Area
>git commit
Repository
a git commit is a checkpoint in the repo
it’s one of many
consider it your many savefiles
git isn’t a method of saving a files
it’s something you do after the files are saved
like a super-save or something like that
first, you change, create, delete files
then you “add” the changes made selectively for your commit.
so if you change 7 files but only 5 are ready, you can choose to only commit the 5 to the commit, the new savepoint
this is not a broad tool. it is tweezers of time
Staging Changes With Git Add
Workflow
Work on Stuff
Add Changes
Commit
once you’ve edited a file, if you run git status
git status will notice and call out the edited files that have been changed since last commit
but you still have to git add them
They are “untracked files”
Three Locations
Working Directory
the directory you’re actually working in, changing files, moving stuff around, etc.
Staging Area
this is the holding area for files that are soon to be committed
Repository
this is there all the commits exist.
as you make more and more commits with new snapshots of the files from the working directory, the repo will expand with more history
a commit is a savepoint. the repo is the save folder
when we make a commit, the contents of .git folder get changed
adding files to the staging area
>
git add file1.txt file2.txt
after adding files to the staging area you can run git status and see them in the “Changes to be committed:”
Finally, The Git Commit Command!
Before you run commit, you are expected to include a message that describes a summary of the changes included in that commit
name the savefile
how to write a good commit message?
running git commit will commit all staged changes
but it will also open the text editor you selected on install and prompt you for a commit message
if you forgot to change it from vim you will get trapped
just give git the commit message at the same time with the -m flag
>
git commit -m “commit message”
once you’ve committed it
git status will return and say
“nothing to commit, working tree clean”
everything you’ve done in the folder, it knows about, has tracked it, and can confirm it’s up to date
as soon as you change a file, the working tree is no longer clean
The Git Log Command (And More Committing)
Work on Stuff
Add Changes
Commit
There is a difference between existing files that have committed once before and have now been modified, and completely new files
git status will flag previously committed files that have been modified as such
git status will flag new files that do not exist in the repo under any commit as untracked
when you add these, and then git init
they will be flagged as “modified” and “new file”
find a log of all the commits for a repo
>
git log
>git log
$ git log
command
commit ed3c39d7bd34be1a23109ce194c33616400c969d (HEAD -> master)
commit hash, not important right now
Author: fishPointer <iantralmer@gmail.com>
username and email address, as configured earlier
Date: Wed Jul 5 13:03:01 2023 -0700
created two files
date and time and commit message
If you want to just add everything in the folder at once for a global commit. no need to be surgical. use git add .
global git add
>
git add .
Committing Exercise
just making files, editing them, committing, and repeating
5
Commits in Detail
What Really Matters In This Section
gitignore is critical
atomic commits, good commit messages, and navigating git docs
Navigating The Git Documentation
git commit has many many options and flags you can use
most git commands have a billion options like this
git docs do include examples
if you don’t want to use a reference and want a sequential coverage of git’s documentation, there’s also the Pro Git Book
try and stay sane reading these docs
Keeping Your Commits Atomic
atomic means to keep each commit focused on a single thing
keep your commits indivisible into smaller parts. just one change.
so if you make a new folder
and search and replace across four files
those things should be separate commits
the folder is one commit
the search/replace is a different commit
this is what it means to keep your commits atomic
!
When adding a directory, to add all the things within that directory and not just the directory itself
git add Directory/
make sure you include the slash at the end
Atomic commits makes it much much easier to rollback code
It also keeps the commit messages simple, since the changes they’re describing is simple
Commit Messages: Present Or Past Tense?
Official git documentation states to use Present Tense Imperative Mood
That is
Do This:
“Make xyzzy do frotz”
And Not This:
“This patch makes xyzzy do frotz”
“I changed xyzzy to do frotz”
Write the commit message as though you are giving orders to the codebase to change its behavior
But it’s a little unintuitive, so just do what your company says
Escaping VIM & Configuring Git’s Default Editor
you can change the default text editor Git is pointing to with a command
git config –global core.editor “code –wait”
there are other options like “vim” and “codium –wait”, Wordpad, etc.
These are included on the git docs for setup and config commands
Probably one for NPP too
There are COMMIT_EDITMSG files that’ll get opened if you don’t -m
You can include lots of info in there with #comments if you want.
You can also make the returned commit message really annoyingly long
Only in advanced and complicated projects will you need to write long commit messages
A Closer Look At The Git Log Command
when we git log, we sometimes want the commit hashes
we’ll use the hashes to revert to those commits
git log docs
crazy number of options for ordering, sorting, and filtering the commits listed in git log
you can git log –pretty in order to format the commit logs in a number of different ways, like for emails, or to fit on 80char terminals, etc.
git log –oneline
will output an abbreviated version of the commit hash, followed by the commit message, and nothing else. one line per commit. gorgeous
$ git log –oneline
31b1ed1 (HEAD -> master) add items needed to grow potatos
91915c2 add items needed for garden box
0e20858 add ingredients for tomato soup
even if your commit message is super long in full, the first line should still be an appropriately brief summary
in the case of –oneline, that’s all that gets shown anyway
Committing With A GUI
gitkraken can open several repos in different tabs like a browser
when you have a repo open, and some changes get made
a new node will appear on the timeline labeled WIP
and it’ll point out files have been changed. you can view them and start the staging process for a commit from there
it seems like it updates live too, since I touched to create a new file and it showed up right away on the GUI without any need to manually refresh
this is actually pretty awesome
keep in mind git log –oneline puts the most recent commits at the top of the list
the diagrams of the GUI are most useful for branching and merging
Fixing Mistakes With Amend
you can amend a commit if you forget to import a file
or to revise the commit mesage
example
git commit -m ‘some commit’
git add forgotten_file
git commit –amend
Core Command here is
>
git commit –amend
ONLY WORKS ON MOST RECENT COMMIT
Can’t go back like 10 commits.
The –amend flag will repalce the tip of the current branch by creating a new commit. It basically just redoes your last commit with the new data
after you do the bad commit
stage the files you need
then git commit –amend
this opens the text editor
from here you can edit the commit message file.
if you have no changes for the commit message file, you can just save and close to move forward
but notice that the newly staged forgotten_file will now be in the autogenerated commented description text
Ignoring Files w/ .gitignore
there are sometimes files and directories you want git to completely ignore
you can use a .gitignore
if you have like, API keys, or sensitive info, or credit card info, you obviously don’t want that stuff uploaded to github and publicly available for other people to download and work with
mac computers also generate fluff files you’re better off ignoring
if you have some code that logs output text, you can just ignore that since it’s going to get regenerated anyway
python dependencies and stuff should also be ignored
there could be thousands of libraries that really don’t need to be part of the repo
create a file called .gitignore
recall that’s a hidden file
three options for flagging files to be ignored
.DS_Store
will ignore files named .DS_Store
folderName/
adding the / at the end will ignore an entire directory
*.log
will ignore all files with .log extension
virtually every project on github will have a .gitignore
once you create the .gitignore file, and add some content to it to filter out other files in the repo
the repo will no longer flag the secret files as untracked in git status
but the repo will still flag .gitignore as untracked, since it is a new file
this is normal. you’ll have to commit the creation/changes to .gitignore just like any other file
There are useful tools like gitignore.io that can actually generate recommend .gitignore file contents depending on the environment you’re working in like Python, JS, etc.
6
Working With Branches
What Really Matters In This Section
conceptual understanding of branching
git head
git branch, switch, checkout
Introducing Branches
every commit has a hash
and every commit also references at least one Parent commit that came before it via its hash
except the initial commit ofc
say you have to tear apart the code to find a bug
but you’ve also been tasked with doing color scheme variations
and someone else has to add a new feature
and someone else is overhauling the UI
etc.
this is what branching was made for
for parallel works
without branching we’d be trapped in linear, serialized code changes
when atomized, it means that it’d be effectively impossible for multiple software developers to work simultaneously
The Master Branch (Or Is It Main?)
in git you are always on a branch
On branch master, nothing to commit
what you get from git status
you’ll also see the color coded “master” text
there is nothing special or unique about the master branch
many people treat the master branch as special
as the official branch or source of truth,
but that is a choice
from git’s perspective, it is not special
The master->main change is only on github
on git, they still use master
if you make an experimental branch and decide not to merge it back to your master branch, you can just let it sit there forever. no need to clean it up or anything
it’d be worse if you did, you lose info
(HEAD -> master)
What On Earth is HEAD?
(HEAD -> master)
The HEAD is a pointer that references the current Branch
When you switch from one branch to another, the HEAD is the thing that points to a different branch
So, if you make a new commit, it’ll go onto whatever branch the HEAD is pointing to
Each commit is uniquely identified by its hash
Each branch is a pointer that points to a specific commit
Two branches can be pointing to the same commit
In a case where you create a new branch but haven’t done anything else yet
Both branches exist, but no commits have been made to diverge them
In order to diverge them, a commit must be made after switching the HEAD
the HEAD will always point to the most recent commit on a given branch
it’s the tip of the branch or the head of the branch
You can also think of branches in terms of multiple people reading the same book
they all have their own bookmarks
when you open the book, it can only be opened to one page at a time
which bookmark do you pick to open to a particular page?
which branch do you pick to point your commits to? That is the info contained by HEAD
Viewing All branches With Git Branch
list of current branches
>
git branch
the currently active branch will be marked with a *
create a new branch
>
git branch <branch-name>
it makes a branch. do not include spaces in the name of the branch
this will only make the branch, it will not switch you to it
Creating & Switching Branches
if you create a new branch and have yet to create a commit to diverge it from the master branch
when you run git log, and the most recent commit is flagged as (HEAD -> master)
it will also list the second branch you created, since both branches are pointing to the same commit
(HEAD -> master, pbj)
Switch branches in git
>
git switch <branch-name>
Used to be checkout
what changed? not the same?
so once you switch to the other branch, and run git log
it’ll reference the active branch first, and any other branches currently referencing the same commit afterwards in the list
that is
(HEAD -> pbj, master)
After making a commit to diverge the branches, the HEAD will be pointing to pbj alone, as it now has a unique commit from the master branch
and the (master) will leave the HEAD list and show up further down the commit history on the most recent master commit
Since git log provides a chronological, serialized list of commits, it’ll flag the most recent commit in each branch that exists (according to the perspective of the active branch)
Time travel aspect:
if you git switch back to master
and run git log
It doesn’t know about the new pbj branch’s commit
Its timeline ends with it’s most recent commit
GIT LOG WILL RETURN DIFFERENT RESULTS BASED ON THE BRANCH
git log is a serialized list of commits that culminate in the most recent commit of the active branch
More Practice With Branching
The current location of the HEAD and the branch it is on when you create a new branch is important
Critically Important!!!
tech:
git commit -a -m “commit message” to just add and commit all unstaged changes
git log is starting to jam up my CLI. I don’t know how to fix it when that happens
so I’m just running git log –oneline instead
asked chatgpt, it’s q to exit
so if the head of a branch hasn’t moved since you created the new branch
then the head of that branch will be flagged in the new branch’s git log
but if you go back to the original branch and make a new commit, the head of that branch is no longer in the common history of the two branches, and so it won’t show up when you run git log on the new branch
IT DOES MATTER WHERE YOU BRANCH FROM
Switching Branches With Unstaged Changes?
the exact same functionality of git switch
>
git checkout <branch-name>
but it can do a lot more than just switch
It did too many things, so they simplified with switch
old docs will reference checkout
git checkout can do more than switch branches, it can restore working tree files too
git switch can create a new branch
>
git switch -c <branch-name>
-c flag lets you make a new branch and switch to it in one line
you can do the same thing with git checkout, but it takes -b for branch instead
>
git checkout -b <branch-name>
when you switch branches it will actually go into your folder, edit and delete and restore files to match what you’re expecting
so if you go into one branch and make a new file, that file will be deleted when you switch branches
but, it can only do that if it’s a tracked file that’s been committed onto a branch at least once
If you have unstaged changes on a particular branch and then try to switch to a different branch, it will warn you that the act of switching branches will overwrite and delete your uncommitted changes.
$ git switch pbj
error: Your local changes to the following files would be overwritten by checkout:
playlist.txt
Please commit your changes or stash them before you switch branches.
Aborting
so if you have to either stash or commit
how can you switch branches in order to reset your changes?
Deleting & Renaming Branches
create branch
>
git switch -c newbranch
delete branch
>
git switch -d newbranch
you cannot delete the branch you are on
-d will only work if the branch to be deleted has been fully merged into an “upstream” branch
-D is necessary for a force-delete
if you create a branch and immediately delete it, it’ll work because it’s technically merged (the master branch head and the new branch head are pointing to the same commit)
Renaming branches uses -m, which means move/rename
moniker? lol
rename a branch
>
git branch -m newname
in order to rename a branch, it must be your active branch
you don’t specify a target branch, just the new name
How Git Stores HEAD & Branches
optional video
just some behind the scenes
in the .git folder theres a file called HEAD
it will reference a file within the /refs folder
the refs/ contains a heads/ folder
the heads/ folder contains files for each branch
these branch files simply contain the hash for the most recent commit for each branch
Branching Exercise
easy stuff, already did more complicated work during the lectures
7
Merging Branches, Oh Boy!
What Really Matters In This Section
basically everything
especially resolving merge conflicts
only one command, merge, in this section
An Introduction To Merging
first, you merge branches, not commits
second, you merge into the current HEAD branch
that is, merge acts to merge the target INTO the current branch
so you should merge your features INTO master, by switching to master and then
how to merge a bugfix into master
>git switch master
>git merge bugfix
if merging a branch into master just involves “catching up” it’s called a fast forward merge
that is, if the master branch hasn’t seen any commits since the branch point for the secondary branch
it gets trickier when master has its own commits that bugfix branch doesn’t have
Performing A Fast Forward Merge
a fast forward merge is not a distinct command
it’s just a name we use for those conditions, when the master is catching up and there’s no work on master that could conflict with the branch absorbed
after a merge the branch does not go away
it still its own distinct context and distinct work can be done on it, and then merged again
at the moment of the merge, they contain the same info
or rather, each branch pointer is pointing to the same commit.
Visualizing Merges
gitkraken time
walked through the same example from the previous video, a simple fast forward merge, but with git kraken showing how the branch pointers point to the same commit after the merge
Generating Mege Commits
if both branches contain novel information, or conflicting information, there’s a chance git won’t be able to perform the merge automatically.
for example, if you both edit line 59 to be different things
when it’s not a ff merge and it’s not a conflict merge, but there are novel data from each branch
git will create a “merge commit”, so that there exists a commit that contains both sets of data from the two parents of the merge,
and that will be the commit that the master of the merge will now be pointing to
the secondary of the merge will remain where it is at, the branch pointer doesn’t move
it never did move, it just so happened that master and secondary started pointing to the same commit, but with the merge commit, there’s a new one for master to point at that secondary won’t be privy to
every commit has a parent
a merge commit has two parents
when you do perform a merge that generates a merge commit, you will have to provide a commit message like usual for it.
-m flag should suffice
that is,
>git merge branch2 -m ‘merge branch2’
the git return will discuss some “recursive strategy”
Oh No! Merge Conflicts!
when there’s a conflict,
git will tell you that it could not resolve the issues automatically
then, you will have to resolve it manually
it will create a modified version of the file that has both versions of the data, the one from the extant branch, and the one from the absorbed branch
in a format like this
HEAD<<<<<<<<<<< head content ========== branch1 content >>>>>>>>>branch1
Given the material from both, you can choose to keep one or the other, mix and match, or write something new to get them to cooperate.
Once you remove the conflict markers and save the document, you can add your changes and commit.
Resolving Merge Conflicts
when you delete a branch, it will warn you that all the changes contained within that branch haven’t been merged into master,
unless they have…
one technique for merging is to create a novel combo branch so that both parent branches can remain independent. just create a third branch for the merger
Using VSCode To Resolve Conflicts
just another merge example
Merging Exercise
doing this one
1. Fast Forward Merge
make a repo
create a fork branch
make updates on the fork branch without changing the master
switch back to the master
merge the fork branch into the master
this is a fast forward merge
2. Merge Commit – No Conflicts
make a new file on a new branch
make changes to the first file on the original branch
switch back to the original branch
merge the two, now the original has both files
no conflict merge, but not a ff
3. Conflict
8
Comparing Changes With Git Diff
Introducing The Git Diff Command
git diff helps us understand the differences between commits, files, branches, etc.
git diff, git log, and git status are all tools to help get a good picture of how a file or a repo has changed over time
like git log and status, it is informative and has no affect on the repo
git diff on its own lists all the changes in the working directory that are NOT staged for the next commit.
where git status will just tell you the files that have been modified,
git diff will actually print out a bunch of text lines, labeled with the line number ranges, of the changes you made,
and mark the removed lines with — flags
and mark the new content with ++ flags
and even color them red and green
the rest of the printout is just there for context.
A Guide To Reading Diffs
format is dense and highly syntaxed
you can diff between two versions of the same file
in the simplest case, between the working directory and the staging area
but you can also diff two different files
or two different branches, or two different commits, etc.
“diff –git a/rainbow.txt b/rainbow.txt”
if you git diff in a repo with multiple files that have been changed, it will list off a git diff for each file
the markers
— a/rainbow.txt
+++ b/rainbow.txt
the markers indicate which file the content came from
the code chunks are called chunks
they’re just there for context
the code chunk line number range things are broken down like this
@@ -3, 4 +3, 5 @@
notice the lack of comma after 4
what it’s saying is
from “-” which refers to file a
line 3
and then four lines after that
from “+” which refers to file b
line 3
and then five lines after that
this is called a CHUNK HEADER
Viewing Unstaged Changes
next up
git diff
git diff HEAD
git diff –staged
git diff –cached
git commit -am only works if the file exists on the previous commit
that is, it won’t work on the very first commit of the repo
Viewing Working Directory Changes
git diff HEAD
when we do git diff HEAD
it’ll show the changes between now and HEAD
HEAD being the last commit, it’ll show you all changes in the working tree since your last commit
the difference here is that
if you have uncommitted changes,
git diff HEAD will show the changes even if they’ve been staged using git add
but git diff will only show unstaged changes
git diff HEAD includes staged and unstaged changes
he used git diff HEAD on a new file that didn’t exist in the previous commit,
but mine didn’t do that
neither git diff nor git diff HEAD would detect it before staging
and then after staging, only git diff HEAD detected it
which conflicts with the rules above
Viewing Staged Changes
git diff –staged
git diff –cached
they do the same thing
they will show ONLY staged changes
git diff will only show unstaged changes
git diff –staged will only show staged changes
git diff HEAD will show both unstaged and staged changes
Diffing Specific Files
you can do like
git diff HEAD style/main.css
that way the git diff doesn’t list off every single file that has changes
and you can just view the changes on a single file
Comparing Changes Across Branches
git diff branch1..branch2
you like. actually put the double dot
then it’ll go through and compare all the files in each branch for you
and files that only exist in one branch will have everything in red, or green, as flagged per file A or B respectively
so it’s pretty straightforward
you don’t have to use the .. you can just use space but people are fans of .. for some reason
order matters, but it just flips the A and B file notations
Comparing Changes Across Commits
git diff commit1..commit2
since commits aren’t named you have to use the hash numbers
which is kind of a pain to copy paste in
example
$ git diff c083591..1a9a55b
Visualizing Diffs With GUIs
this is one of the areas where GUIs shine
git kraken will offer file view and diff view when you’re staging changes
you can also just ctrl+click two files and it’ll automatically offer a diff between them
or two commits
sometimes people call the code chunks, hunks
Diff Exercise
running git clone for this one
Note: DO NOT RUN GIT CLONE INSIDE A REPO
git clone creates a repo on your local using the link
which means if you do it in a repo you are making the rookie mistake of creating a repo within a repo
git clone https://github.com/Colt/git-diff-exercise
why is there a hidden branch
are they not on your machine until you switch to them???
completed exercise, was a good one
9
The Ins and Outs of Stashing
What Really Matters In This Section
some people just don’t use git stash
pretty optional
Why We Need Git Stash
since branches restructure the files and folder on your machine
if you make changes on a branch and then try to change the branch without committing them, there are two options
1. the changes go with you to the new branch
2. git detects a conflict and won’t let you switch
sometimes you need to switch to another branch before you’re ready to commit on the stuff you’re working on
so you stash it
in scenario one, if you switch back to the original branch and commit, the changes won’t exist on master
only one instance of the changes, and it carries with your HEAD
Stashing Basics: Git Stash & Pop
the command is
> git stash
or
> git stash save
it will take all uncommitted changes and stash them, and then revert the changes in your working copy so you can switch branches without conflict
seems really useful
> git stash pop
is what pulls it out of the stuff and puts everything back on the table
Practicing With Git Stash
Git Stash Apply
git stash apply
most people if they use stash at all will just stash and pop
no fancy stuff
>git stash apply
so after you’ve stashed some changes
you can switch branches and go somewhere else
but if you decide you want to pop out those stashed changes onto a branch other than the one you stashed them on
you can use git stash apply, and then it’ll act like a normal merge operation where you have to manually resolve conflicts, etc.
it also doesn’t remove them from your stash
pop pulls it out, applies it, and clears the stash out
git stash apply pulls out a new instance of it, and applies it while retaining the stash
Working With Multiple Stashes
you can just keep stashing stuff
over and over
>git stash list
to view all the stashed changes
not super practical
you can pop particular stashes in the stash by reference the stash by the stash id
stash@{2}
Dropping & Clearing The Stash
>git stash drop stash@{2}
this is how you just delete a stash entry
>git stash apply stash@{2}
to completely empty the stash
>git stash clear
Stashing Exercise
Done
Had to leave for a week, so I came back and walked through this example again
10
Undoing Changes & Time Traveling
What Really Matters In This Section
many commands covered in this section
Checking out Commits and Escaping Detached HEAD
both critical
restore, reset, and revert are all different
Checking Out Old Commits
git checkout is a swiss army knife,
people thought it had too many features
so they created git switch and git restore
you can
>git checkout <hash>
you only need the first seven characters of the hash to properly checkout
so git –oneline can provide that
when you checkout a hash like that, you enter a detached HEAD state
you can look around
make experimental changes
commitn them
you can also discard any commits from this state
without impacting other branches
by switching back to a branch
after checking out the hash of a previous commit, you can check git status and log and see that you have time traveled to when that commit was the most recent commit
HEAD detached seems to just mean that you’ve time traveled.
recall: HEAD points to the BRANCH REFERENCE
the BRANCH REFERENCE points to the most recent commit on the branch
When you time travel, you disconnect the HEAD from the BRANCH.
The branch reference is always at the tip, the most recent commit.
whenever HEAD is pointing directly at a commit, and not at a branch, then this is considered detached HEAD
you can also confirm it’s pointing directly at a commit hash and not a branch in .git/HEAD
Re-Attaching Our Detached HEAD!
simplest way to reattach your head is to just switch branches
>git switch master
moves the HEAD back to the BRANCH reference at the tip of master
this detached head will also show on the GUI for gitkraken
when in detached head, you can do 3 things
1. stay in detached head, exame, poke around, etc.
2. leave and go back via git switch, canceling changes
3. create a new branch from this point and switch to it
when you do #3 and create a new branch from that point, you can now make and save changes that are retained, since HEAD is no longer detached. It is now pointing at a valid branch reference
this is how you can time travel backwards and take a new path forward.
Referencing Commits Relative to HEAD
>git checkout HEAD~1
think of this as a relative index
that is, HEAD – 1, or the commit immediately before the one HEAD is currently pointed at
History
Commit 1
HEAD~3
Commit 2
HEAD~2
Commit 3
HEAD~1
Commit 4
HEAD
wonder if HEAD~0 works
it does work. You detach your head and point at the directly at the commit, even though there is an available branch reference pointing at the same commit
you can re-attach your head quickly with
>git switch –
this will simply return you to whatever branch you were on when you originally detached the HEAD
Discarding Changes With Git Checkout
say you are working normally, no detached head time travel funny business
you’ve edited a file and decide none of the changes are going well, you’d like to revert that file back to where it was when you started
that is, revert that file back to the last commit, how you found it
>git checkout HEAD <filename>
this will check out the version of that file within the commit that the HEAD is currently pointing at.
So this can be used when you’re editing several files, and you’d like to revert specific ones
kind of like clearing just one of several whiteboards with notes on them.
another shorter version to this is
>git checkout — <file>
just like >git switch –
it automatically reverts the named file back to whatever HEAD’s commit has
Un-Modifying With Git Restore
git restore can do that checkout reversion nonsense
its a newer command
git switch and git restore were both introduced as more specific alternatives to git checkout
you can discard changes on a particular file and revert it back to the last commit
NOTE: THIS COMMAND IS NOT UNDOABLE. ONCE YOU GIT RESTORE, YOU CANNOT GET THE DISCARDED CHANGES BACK
>git restore dog.txt
will restore dog back to HEAD
you don’t have to specify HEAD with this one
You can also reference a particular commit with the checkout
git restore –source HEAD~1 dog.txt
>git restore –source <commit hash OR HEAD~n> <filename>
again this deletes those changes
Un-Staging Changes With Git Restore
git restore can also unstage files
when you git add, for whatever reason there doesn’t seem to be a git remove
git restore does this for you
>git restore –staged <filename>
it actually tells you about this in git status
(use “git restore –staged <file>…” to unstage)
you can git restore –staged .
to remove everything from the staging area
just as you git add .
to add everything to the staging area
you don’t have to remember this, because git status will tell you every time
but it doesn’t tell you that you can select the manually source of the restore function and not just default to reverting to HEAD
>git restore –source HEAD~1 dog.txt
Undoing Commits With Git Reset
>git reset <commit-hash>
sounds similar
resets a repo back to a particular commit
git reset is how you undo commits
say you made 3 commits on the wrong branch and you need to delete and undo those commits and get them off the record for that branch
>git reset <commit-hash>
will revert the branch and commit history, and delete all time that has passed since that commit
it doesn’t revert the files, it just deletes the commit history
meaning, if you delete commits 4 and 5 with a reset function
the changes to the files made in 4 and 5 will persist
this sound annoying, but it lets you keep the work and move it to another branch
that way you can make a new branch, store those bad changes on a different branch, and then move on as normal from the commit
there are also hard resets
>git reset –hard <commit>
if you’re absolutely sure you want to delete both the commits AND the file changes, use hard reset
>git reset –hard HEAD~1
will delete the last commit and the changes made within it
if there is a branch forked off of a commit sometime after the commit you’re hard resetting to, it won’t get deleted
you are resetting the active branch, MASTER
there’s no reason for the BRANCH2 to have to forget everything, it has it’s own version of the history independent of whatever resets occur elsewhere
Reverting Commits With…Git Revert
git reset moves the branch pointer backwards and eliminates commits
git revert performs similarly to git reset
git revert creates a NEW commit with the unmodified files. it requires a commit message
git revert seems to be more of a historical cloning operation
there are different contexts in which revert and reset are more useful
note that when you git revert <commit>, the commit you reference is the one whose changes you want eliminated
not the commit you want to revert TO
if you want to reverse commits that other people already have on their machines, you should use revert
if you reset and delete those commits from the shared history, things will get confusing because people will still have local versions of the erased commits
so it’s better to keep everything in the log, and create a revert version on the commit history
that way everybody’s changelog lines up
reverting a commit can also create conflicts
git may not know what to keep and what not to keep
this concludes the core git functionality segment of the course.
Undoing Changes Exercise
Actually a really good exercise
11
Github: The Basics
What Really Matters In This Section
Everything in this section is Critical
What Does Github Do For Us?
it is a hosting platform for git repos
hosting, collaborating, file backups
alternatives include GitLab, BitBucket, and Gerrit.
World’s largest source code host
Started in 2008
56 million developers and 100 million repos
Free!
Why You Should Use Github!
Github is really useful even if you’re only working with one other person on a hobby project
Github is the primary home for open source projects
React, Swift, etc. are all there
If you want to do open source, you’ll have to work on github
making open source contributions is great proof that you know what you’re doing
React is a JavaScript Library
Tensorflow is a Machine Learning Framework
Github profile showcases and exposures your projects
You can make friends and professional acquaintances this way
it’s vaguely social networky
You can stay up to date on living projects you’re invested in
Frameworks, etc.
Cloning Github Repos With Git Clone
Cloning is the creation of a local copy of an external repo
using a URL
MAKE SURE YOU ARE NOT INSIDE OF A REPO WHEN YOU CLONE!!!
>git clone <url>
you get the source code and the git history
all the commits, all the files
when you run git clone
it will make a new folder for you
git clone is a git command. it is not tied to github
there are other codebases that are not github. you use git clone for those ones as well.
Cloning Non-Github Repos
if you can see it, you have permission to clone it and do whatever you want to it
doesn’t necessarily mean you are allowed to repackage it and resell it though
you’re not allowed to just push changes up to a repo somebody else owns
there are protocols for this process
if you read the documentation for git clone, there is not a single mention of github
Github Setup: SSH Config
Secure SHell
authenticate your terminal
1. generate an SSH key
2. tell github about it
https://docs.github.com/en/authentication/connecting-to-github-with-ssh/generating-a-new-ssh-key-and-adding-it-to-the-ssh-agent?platform=windows
Guide is liable to change but
keys are stored in ~/.ssh/
verify the ssh agent is active
$ eval “$(ssh-agent -s)”
create a new ssh key
$ ssh-keygen -t ed25519 -C “email@gmail.com”
add the key to your list of keys
$ ssh-add ~/.ssh/id_ed25519
id_ed25519 is the name and can be changed. not sure why it’s that
then cat, to reveal and then copy that hash
paste it into the add SSH key prompt in your github account settings
Creating Our First Github Repo!
existing repo
if you already have something on your local machine you want to put on github
1. create a new repo on github
2. connect your local repo, “add a remote”
3. push the changes up to github
if you are starting from scratch
create a brand new repo on github, and then clone down the empty onto your machine
work locally, then reupload
if you start the blank on github, then you won’t have to link the local instance to the cloud instance
click create repo
A Crash Course on Git Remotes
in order to push code up to github
or any other hosting platform
we first need an initialized git repo somewhere on our local machine
since we’re uploading to some far off platform
the code has an external destination, so we set up a remote
remote meaning, remote destination, which is designated by the URL
these destinations are the remotes, and consist of a URL
push, puts code up there
fetch pulls down
>git remote -v
lists the remotes/destinations the repo knows about
works with
>git remote
as well,
-v makes it verbose
the -v will show a (fetch) and (pull) link
meaning you can pull and push to difference locations
the name of the remote will probably be “origin”
>git remote add <name> <url>
lets you add a remote given a name and url
Origin is conventional, not special in any way
similar to how the Master branch is just a conventional name
so now, example of pushing an existing local repo up,
onto a new repo i just created on github
it provides instructions for this:
…or push an existing repository from the command line
git remote add origin https://github.com/fishPointer/psychic-octo-rotary-phone.git
git branch -M main
git push -u origin main
first, add the remote
then you can use plain >git remote to check your work
you can rename and remove
git remote rename <old> <new>
git remote remove <name>
Introducing Git Push
>git push <remote> <branch>
you have to specify which remote
and which branch to push
so you won’t necessarily want to push all your branches
and you may not want to push the branch you’re currently on
though often people just push their master branch
thus the common command is
>git push origin master
stupid ass github won’t let me login using my username and password
it’s not “secure enough”
made me go into an obscure developer settings menu and generate a fine grained personal access token and manually select the 1. permissions, 2. repo context and 3. expiration date
so i made one with all permissions, all repos, and 1 year
now i can push
nope, it’s asking for the login every time
From Stackoverflow
Make sure you are using the SSH URL for the GitHub repository rather than the HTTPS URL. It will ask for username and password when you are using HTTPS and not SSH. You can check the file .git/config or run git config -e or git remote show origin to verify the URL and change it if needed.
using the ssh URL to initialize it worked fine.
—
you don’t push commits, you push entire branches
Touring a Github Repo
can switch branches
view commits
comment on commits
visually see commit changes
etc.
Practice With Git Push
basic workflow
make changes
>git add .
>git commit -m “message”
push up to github
>git push origin master
A Closer Look At Git Push
if you create an empty repo on github
and then create an empty repo locally
all you need to do to connect them is tell the local repo about the remote
there’s a distinction between the branches you have locally and the branches you have on github
there are two “master”s, one local, and one remote
you can use
>git push <remote> <local-branch>:<remote-branch>
in order to specify which local branch should be pushed to which remote branch
that is,
git push origin pancake:waffle
will push the local pancake branch up to the waffle branch on the github repo
so if you make a new branch locally and just
>git push origin cats
it will create a remote branch called cats in order to push cats(local) onto cats(remote)
that is,
>git push origin cats == >git push origin cats:cats
note that if you push cats:master
the one on github will have the contents matching your local “cats” branch, but github will still list it as “master”
What does “git push -u” mean?
git push -u origin master
-u lets you set the upstream direction of the branch
that is
if you’re using
>git push -u origin master
then it’ll designate origin master as the remote and branch as the upstream destination
it’ll remember this
such that next time you run just
>git push
it’ll automatically target origin and master
the upstream desgination -u is per branch
so if you have branch dogs locally and on the remote repo
then git push -u origin dogs
will LINK together the two dog branches
such that you can just “git push” with no further specification
you can also set the upstream to be a different branch using the same local:remote syntax
>git push -u origin dogs:cats
Another Github Workflow: Cloning First
option 2 is starting from scratch, cloning the empty repo down to your machine
you will get a warning: you appear to have cloned an empty repository
the reason to do this is it comes with a preconfigured remote
Main & Master: Github Default Branches
2020 they renamed master to main
if you initialize the repo on github site, and include a readme, there will be a file, meaning the branch will exist. and it’ll default to main
if you just init an empty repo on github web, there will be no files and no branches, until you do your first push
github’s recommended commands include a rename line for main
>git branch -M main
and then
>git push -u origin main
Github Basic Exercises
need to refresh on merging and time traveling
12
Fetching & Pulling
What Really Matters In This Section
Remote Tracking Branches
Git Fetch
Git Pull
they’re all critical
Remote Tracking Branches: WTF Are They?
recall that a branch is just a pointer that references a specific commit
when you clone a repo down to your machine
there are two pointers
first, the active one. you add a commit, the branch reference will point at that most recent commit
second, the remote tracking branch
this one is fixed and will point at the commit that the branch was referencing when you cloned it
that is,
“At the time you last communicated with this remote repository, here is where branch X was pointing”
that’s the information contained by the Remote Tracking Branch
their nomenclature is <remote>/<branch>
so we usually add the remote with the name “origin” and the default branch is usually “master” so the remote tracking branch is usually
origin/master
other example
upstream/logoRedesign
references the state of the logoRedesign branch (at the time of cloning)
on the remote named upstream
>git branch -r
will list the remote tracking branches in the repo
Checking Out Remote Tracking Branches
as you add commits, the remote reference will stay where it’s at
otherwise what’s the point of it lol
once those two references diverge because you added a new commit
>git status will tell you
Your branch is 1 commit ahead of origin/main by 1 commit
you can go detached head by
>git checkout origin/master
and go see what the repo looked like when you first cloned it over
recall git switch – to go back
once you push, you’ve interacted with the remote branch
and so the remote tracking branch will be updated as well
Working With Remote Branches
workalong exercise
when you clone a repo
you’ll open it up and check the list of branches
and even if there’s a dozen branches on the github repo
>git branch will yield only main/master
but if you run
>git branch -r
you’ll get to see all the remote tracking branches as well
you could >git checkout origin/puppies
and go into detached HEAD, but you wouldn’t be able to post changes
when you clone the repo, there’s automatically a connection between local/master and origin/master
so if you want to work on a different branch, that connection needs to be made for local/puppies and origin/puppies as well
the newer git switch command has this functionality built in already
>git switch <remote-branch-name>
creates a new local branch with matching name
AND
sets it up to track the remote branch origin/<name>
does both
recall to create a new branch you usually need to add the -c flag
>git switch -c newbranch
so in this case, without the create flag, it will only work on branches it knows exist remotely
Output
Branch ‘movies’ set up to track remote branch ‘movies’ from ‘origin’.
git switch fjaskldfj won’t work
it used to be
>git checkout –track origin/puppies
guessing this would create the track when you did the checkout, so you wouldn’t go into detached HEAD
Git Fetch: The Basics
git fetch time
fetch and pull are different
fetch will clone the most recent version of the remote repo into the local repo
pull will clone the most recent version of the remote repo into the working directory
so, if you have a local repo you’re working on
and your master branch is ahead of the remote one by 1 commit
but then somebody else pushes a change up to the remote repo, and now there are 3 new commits your machine doesn’t have
you can clone those onto your machine using git fetch
>git fetch <remote> <branch>
you don’t have to specify a remote or a branch, it will default to origin and all branches
so once you run git fetch, your “origin/master” branch will have the newly downloaded 3 new commits, while your HEAD and “master” branch will remain distinct and in its own branch.
now you have access to the most recent changes in the form of another branch called “origin/master” but the stuff you were working on hasn’t been affected
note that when we created the remote tracking branch earlier, that technically counted as a branch with no new commits, thus its branch head wasn’t shown to diverge
Demonstrating Git Fetch
note that
when you git clone
origin/master does not update dynamically with everything else going on in the world
git is not always online like that
if you want to see the most recent version of origin/master
you run git fetch
that’s what it’s for
pinging the remote repo for updates
so if there have been 100 new commits on the remote repo
and you run git status on your local repo
it will say you’re up to date
because the remote tracking branch origin/master has not been updated
similarly
if you git fetch and get those 100 commits
git status will now tell you that your local master branch is 100 commits BEHIND origin/master
and can actually be fast-forwarded (git pull foreshadowing)
Git Pull: The Basics
pull will move your HEAD too
fetch won’t move your HEAD
git pull = git fetch + git merge
>git pull <remote> <branch>
where we run git pull from does matter
because that branch will get merged into by the latest versions
git pull can and will result in merge conflicts
because your version has changes that will conflict with the recent updates
Git Pull & Merge Conflicts
same stuff
git pull merge conflict walkthrough
A Shorter Syntax For Git Pull?
if you just run >git pull
remote will default to origin
branch will default to whatever tracking connection is configured for your current branch
remote tracking connections can be configured manually, but most people don’t mess with that stuff
pull is more dangerous than fetch
Summary
Fetch
gets changes from remote branches
updates the remote-tracking branches with new changes
Does not merge changes onto your current HEAD branch
Safe to do at any time
Pull
gets changes from remote branches
updates the current branch with the new changes, merging them in
Can result in merge conflicts
Not recommended if you have uncommitted changes
13
Github Grab Bag: Odds & Ends
What Really Matters In This Section
Adding Collaborators and Managing Repo Visibility is important
Then, readmes and markdowns
then gists and pages
Github Repo Visibility: Public Vs. Private
public – anyone can see the repo, not everyone can push up to it
private – whitelist
settings tab on a repo only visible to owner
delete/privatize/change ownership all in danger zone at bottom of settings
People usually start private, go public later
Adding Github Collaborators
repo settings has manage access
big green Invite a Collaborator button
person2 gets an email link to accept the invitation to collaborate
permission on both sides
Github Collaboration Demo
You get the idea
What are READMEs?
pertinent information
what the project does
how to run the project
why it’s noteworthy
who maintains the project
github will automatically detect and render the README as the blogpost beneath the list of files when you view the homepage of a repo
almost everyone puts it in the root of their repo directory
has to be all caps
README.md
md is for markdown
succinct and convenient syntax for generating formatted text
A Markdown Crash Course
markdown is a tool that generates markup
text-to-HTML conversion tool
advertised as easy to read and easy to write
check out the markdown file in plaintext to see how easy it is
for drafting with a sidebyside render
markdown-it.github.io
https://markdown-it.github.io/
^^ contains a more perfect reference of all the formatting features than I could write up as the default file
can make codeblocks and automatically color them as syntaxed by a called language
reddit uses markdown
Adding a README To A Project
most of the time when you’re working on a project you don’t really expect anybody to ever see it
recruiters are almost definitely only going to look at the README. Non-technical people will not look at your code
you have to add and commit and push the README just the same as you would any other file
so anyway, make sure you make pretty README files and have a good grasp on Markdown
Creating Github Gists
a simple way to share snippets of code
like pastebin
a microcosm of the repo’s features
gist.github.com/user
you can share your gists
people can fork it, star it, etc.
lightweight version of the repo
no commits and pushes and stuff
just a very fast way to share code
sometimes a gist is more appropriate
btw, you can have non README .md files and have them render formatted text anywhere you want on github repos/gists
there’s also a /discover page where you can just scroll through a feed of random code snippets,,, lol.
Introducing Github Pages
pages hosted and published out of github repos via github
you can make a website easily
static webpages only
no serverside stuff
clientside only, just HTML/CSS/JS
not for high capacity website with lots of traffic
pages.github.com
the domain is github.io
if you see github.io, you are being pointed to a github page
there are user sites and project sites
username.github.io
username.github.io/repo-name
you get one user site
you might use username to host a portfolio or personal website
project sites are unlimited, one for each repo
Github Pages Demo
you can have a perfectly normal project
and then make a branch where you made a github page
you select a branch in the repo
and tell github it has a website for github pages
specifically an index.html file
Then in repo settings, down near delete, you can enable github pages
so make a new branch, add the index.html file, and then point github settings to that index.html in that branch that exists just for the website
it’s perfectly fine to have a project branch at the beginning of time, where the website exists on one branch and the other is the actual project, with virtually no file overlap/merge, etc.
standard name is gh-pages, but not necessary.
There’s also Github Actions now, so they have a workflow for building pages better than this process
https://fishpointer.github.io/psychic-octo-rotary-phone/
that worked
14
Git Collaboration Workflows
What Really Matters In This Section
no new git features or commands
the structure of workflows
take your time and digest this fully
It’s a longer section
Critical
single branch problems
feature branch workflow
pull request – aka PRs
Forking
Fork and Clone workflow
so basically, everything is important
The Pitfalls Of A Centralized Workflow
has the most shortcomings
everyone works on master/main
the most basic workflow possible
no other branches
all work done on a single branch
which will invariably lead to two people working from the same commit
and then one will push first
then the second will get an error
failed to push
updated were rejected because the tip of your current branch is behind its remote counterpart
merge the remote changes(gitpull) before pushing again
that means, you can’t push unless you’ve pulled first
another way of saying that is
you can’t push unless your history matches its history
there’s also no way to share your work in progress with others without pushing up to the (only) branch and basically just breaking it
probably forcing a rewind
so the problems with a centralized workflow are:
lots of time spent resolving conflicts and merging code, scaling exponentially probably with team size
nobody can try anything radically different or experiment without seriously disturbing the main codebase
options for collaboration are very limited. you can’t actually work together on anything without pushing incomplete code up to the master codebase, exposing everyone to access to incomplete code
Centralized Workflow Demonstration
he simulates the workflow on two accounts
lots of setup stuff not relevant to the topic of discussion
another issue with single branch
when someone pushes up their incomplete code for you to review
and you’re also working on your own piece of new code
you have to get rid of your working changes in order to pull down their code
which is something git stash is useful for
but it still is a problem
there’s only one branch, one working directory for each person
again, collaboration options are actually very limited
The All-Important Feature Branch Workflow
better idea
treat the master branch as the all important – never to be touched branch
acts as the official project history
all new work is done on separate feature branches
which are then merged into the master branch upon completion and team approval
no new work is done directly on the master branch
now multiple teammates can collaborate on a single feature and share code without corrupting the master branch
managed properly, the master branch will never contain broken code
branches are feature-oriented, not person-oriented
so its not like “david’s branch” and “pamela’s branch”
the branches are per feature, regardless of who is responsible for it, or how many people work on it
Feature Branch Workflow Demo
people in large corporations have nomenclature and protocols for creating feature branches
something like
feat/navbar
feat for feature, of course
there will be thousand and thousand of feature branches
but not all of them show up on github, because they don’t need to
once they’re merged into master, they’re usually deleted to keep the public work on the repo clean
Merging Feature Branches
so how does the merging work then
you would have your finished feature branch locally
it doesn’t exist on github and it never will
how to merge a feature branch without pushing it to github
pull the latest changes from remote master
create a local feature branch
build out the feature, make some commits
switch to master
pull the latest changes from remote master
merge the feature branch into master
resolve conflicts if any
push master up to remote
seems like a quality control issue
which is what pull requests are for
once the merge is all set in stone
its good practice to delete it off of github AND your local machine
Introducing Pull Requests
Pull Requests AKA PR are a feature built into github, not native to git itself
a mechanism to approve or reject the work on a given branch
faciliates discussion and feedback on specific commits
alert sytstem for work that needs reviewing
“i have new stuff i want to merge into master. what do you think?”
there are also ways to explicitly protect the master branch so it can’t be modified without approval
Workflow
do work locally on feature branch
push feature branch to github
open a pull request to the feature branch you just uploaded
wait for the PR to be approved and merged. start a discussion. team structure stuff. etc.
when you make a PR on github, using the UI
there are several ways really
the PR has a name
it has the master branch, and the branch requesting to merge
you can write a description of what the change is and why, including file attachments, etc.
once you make the pull request, the boss is the one who approved it and hits the merge button
theres a lot of structure and formatting and nomenclature concern for submitting proper pull requests to open source projects
there are often a lot of pull requests on these projects and it may take a while to get things reviewed
also, the PRs effectively act as forum threads or discussion posts
Making Our First Pull Request
if the master branch isn’t protected, then the person submitting the PR can choose to just bypass that procedure and click merge anyway
pretty basic process, but it looks like something you just have to do yourself
experience
Merging Pull Requests With Conflicts
sometimes there are conflicts, of course
the PR will notify you that there are conflicts, and there’s a button to resolve conflicts
sometimes it’s simple enough that you can resolve the merge issue in the browser with the github file editor
but realistically, if you have to address multiple issues across multiple files, it’s probably better to just start from command line
github will give you the command to handle these merge conflicts yourself
Step 1: from your project repo, bring in the changes and test
git fetch origin
git checkout -b new-heading origin/new-heading
git merge main
Step 2: Merge the changes and update on github
git checkout main
git merge –no-ff new-heading
git push origin main
so first you git fetch origin locally
from this, you’ll get new remote tracking branches
recall
fetch and pull are different
fetch will clone the most recent version of the remote repo into the local repo
pull will clone the most recent version of the remote repo into the working directory
as a result of the fetch, you’ll have access to the new branch the other guy (who made the PR) made and pushed up to github
you need a local copy of his work in order to review it properly
from there, you can switch to the feature branch
and then merge in your local copy of the master branch
test it, make sure it works. make a commit
and once you know that the merger of the feature branch and the master branch together is functional
you have all this work on the feature branch still
because you previously merged master INTO feature, locally
so switch back to main
and then merge the feature branch back into master
so yes, you merge feature <- master and then immediately after master <- feature
then on github you get PR successfully merged and closed
workflow
acquire feature branch, resolve conflicts
git fetch origin
git switch feature
git merge master
fix conflicts
merge feature conflictless, push to github
git switch master
git merge feature
git push origin master
after you do all this, and it’s pushed up and the PR is closed
just delete the local/remote versions of the feature branch
cleanup duty
Configuring Branch Protection Rules
repo settings
under branches
configure the default branch
say you don’t want main and master
etc.
then you can add branch protection rules
disable force pushing
prevent branches from being deleted
etc
you can also define branch name patterns
the repo can enforce naming rules for large projects
you can “require pull request reviews before merging”
thats the point lol
Introducing Forking
instead of just one centralized github repo, every developer has their own github repo in addition to the “main” repo
developers make changes and push to their own forks before making PRs
common on large open source projects
thousands of contributors but only a few maintainers
so like a supersystem above feature branches
this system enables anybody to make changes
they don’t need permission from the owners of the repo to become a contributor
a fork is a personal copy of someone else’s repo on your own account
you’re not cloning the repo onto your machine, you’re cloning the repo into another repo that you control
forking is not native to git, but another github QOL feature
Forking Demonstration
if you clone someone else’s repo
you can’t make changes and push it up to github to show someone else
“ah. I don’t have friends these days” LOL
if you want to remix someone else’s code/repo, it’s better to fork it onto your own account, make changes, push them up onto your fork, and then share that with other people
your fork will also say like “This branch is 1 commit ahead of author:master”
so it’ll still keep tabs on the source repo
The Fork & Clone Workflow
so someone else has a repo
then you make a fork of that repo
then you clone your fork onto your machine
now there exists one remote directory for your local machine
origin – which points to your personal fork of the repo
but if the original author is still making changes
and you want to work alongside those changes
you create an additional remote that’s pointing to the official project repo, call it “upstream” or something. “original”
now you can pull and fetch from the official project repo for new updates, in addition to managing your own forked repo
now just because you have set up a remote directory doesn’t mean you can push up to the other guy’s codebase
but you can cultivate your fork and then create a pull request between the forked repo and the original repo
and then from there once it’s approved, you can pull your changes from the official repo
my summary of the workflow
1. pull down changes from official repo onto local
2. make changes on local
3. push changes onto forked repo
4. make a pull request to merge forked repo into official repo
His summary of the workflow
1. fork the project
2. clone the project
3. add upstream remote
4. do some work
5. push to origin
6. open PR
Fork & Clone Workflow Demonstration
if you want your fork to stay up to date, you’ll have to pull from the official upstream onto local and then push up to your fork
every time there’s an update
somewhat mundane, but i can’t think of a better way
Fork and Clone is all over the place
if you look at an open source project’s pull request
you’ll see the pull request as saying like
1 commit into (facebook:master) from (AriPerkkio:fix/plugin-crash)
so you can merge branches from different repos into eachother
which is why forking is a valid collaboration method
wonder if it’s explicitly necessary that it be a fork
15
Rebasing: The Scariest Git Command?
What Really Matters In This Section
one command and only one command
git rebase
these days a lot of people use it
but old school is to avoid it
nothing is critical in this section
but it is part of engineering teams’ workflows often
Why Is Rebasing Scary? Is It?
some companies use it all the time
others avoid it like the plague
two main uses
as an alternative to merging
as a cleanup tool
Comparing Merging & Rebasing
both merge and rebase combine changes from two branches
when you are working on a feature branch
and master gets updated
because the team is very active, and master is changing all the time
if your feature branch is taking a while to get ready to complete
you may need to merge novel changes from master into your feature branch
so you know you’re working with the most recent changes
but if you take a really long time, then your feature branch will end up
riddled with commits that are just for merging in the latest features from master
and the commit history on your feature branch will be hard to parse since so many entries are basically just you trying to pull updates
rebasing rewrites the commit history
and puts all the novel feature commits at the tip of the most recent master branch
it scrubs all those merge commits you made to pull updates from master
and leaves you with a cleaner, more linear commit history
commands
git switch feature
git rebase master
Rebase Demo Pt 1: Setup & Merging
demonstration of him creating a muddied commit history on a feature branch
Rebase Demo Pt 2: Actually Rebasing
rebase generates new commits that didn’t exist before
one for each of the feature branch unique commits
deleting the old master branch merge commits
the rebase is because you change the base of the feature branch to be the tip of the master branch
rebase
each of the merge from master branch commits on the feature branch has two parents
after the rebase, all the commits have just one parent
“rewinding head to replay work on top of it”
rebasing sorts and linearizes two meshed branches
now how to use rebase in place of merging
sometimes its good to rebase before sending something to someone else
so that the commit history they’re looking at is linear
you are not rebasing the master branch
you are rebasing the feature branch ONTO the master branch
The Golden Rule: When NOT to Rebase
cleaner project history,
linear project history
no unnecessary merge commits
the condition you don’t want to rebase on
rebasing rewrites history and generates new commits
the old commit history of the feature branch, and its merge commits are deleted
new commits are created with the contents of each commit of the original feature branch
which means,
if other people have access to the original set of commits from before the rebase
and then you rebase,
you will delete those commits and create a huge conflict between your timeline and theirs
NEVER REBASE COMMITS THAT HAVE BEEN SHARED WITH OTHERS
IF YOU HAVE ALREADY PUSHED COMMITS UP TO GITHUB – DO NOT REBASE THEM UNLESS YOU ARE POSITIVE NO ONE ON THE TEAM IS USING THOSE COMMITS
you have commits that don’t exist in their history
and they have commits that don’t exist in yours
you don’t change the master branch’s commits
you change the feature branch’s commits
so if you’ve pushed it before, think twice
but thankfully the feature branch merge workflow usually does not include pushing the feature branch up to github, until the end. and then it’s scrubbed
if it’s just you working alone, you can rebase all the time
small teams ok too
Handling Conflicts & Rebasing
git rebase –abort
because it manually recreates each commit from the feature branch at the tip of master
it’ll let you know which commit it fails at, because of a conflict
you can resolve the conflict manually as you normally would and move forward, or just abort
you have to git add
and then git rebase –continue
in order to proceed after resolving conflicts
16
Cleaning Up History With Interactive Rebase
What Really Matters In This Section
you can reword, fix up, edit, and drop commits with interactive rebase
none of it is critical though, it’s all nice to have
different from what we do with git
Introducing Interactive Rebase
git rebase is used in two ways
an alternative to merging, we have already seen
as a cleanup tool, which we cover now
any time we rewrite the commit history, we want to avoid doing it on work that other people have access to
good for cleaning up buggy, half-baked, or vague commits – before you share the code with others
a final step to take to polish stuff up before the big reveal to your collaborators
when using interactive mode, you aren’t rebasing onto another branch, like when we would rebase onto master. use
git rebase -i HEAD~4
the -i flag enters interactive mode, and since no branch is specified, it just rebases them onto the HEAD they’re already on
so that means its just a way of recreating commits
the HEAD~4 indicates we’re recreating the last 4 commits on this branch, where the HEAD is currently
since you’re in interactive mode, you can change the name of a commit as it’s recreated, or just choose to drop it and not recreate it
Rewording Commits With Interactive Rebase
So when you actually run the
git rebase -i HEAD~9
it’ll open the text editor and each commit in the commit history will be associated with a function word
List of Function Words
pick
use the commit
reword
use the commit, but edit the commit message
edit
use the commit, but take a moment to amend the commit
fixup
use commit contents, but combine it with previous commit and discard this one’s commit message
drop
remove commit from history
the text editor will also include this key and instructions in the comments
note that gitlog lists the most recent commit at the top
but the interactive rebase editor lists the most recent commit at the bottom
all commits default to pick
you don’t actually edit the commit messages in that text editor
you just change the command words, then save and close
after you save and close the first text editor, a second one opens specifically for editing the commits flagged for reword.
kind of silly but sure
stuff like this makes a good argument for using GUI
note that just rewording, any rebasing function on a commit, recreates the commit, and thus gives it a new hash
Fixing Up & Squashing Commits With Interactive Rebase
fixup will retain the changes in the commit, but meld it into the previous commit/message
squash is a command that melds it but retains the message
fixup is a command that melds it and deletes the message
demonstrate the effect of fixup by comparing the commit changes on the local repo with the commit changes on the github repo, which does not have the rebased version of the work
and of course, fixup on one commit will cause all subsequent commits to get recreated
after fixup as well, the total number of commits will change, you need to HEAD~n a different n
Dropping Commits With Interactive Rebase
note that
at the beginning of the demonstration he created a new branch and rebased on that one
by rebasing on a non-main branch, he was able to keep a copy of the non-rebased work on main.
When he rebased back 9 spaces
the fork point of the branch moved backwards from the most recent commit back to 9 commits ago
good to know, and good for comparing the rebase before and after
17
Git Tags: Marking Important Moments In History
What Really Matters In This Section
not used all the time
not difficult
usually used to tag different releases or versions of a project over time
semantic versioning is the de facto use case for git tags
very straightforward
The Idea Behind Git Tags
branch references change if you add a commit
a tag is like a branch reference, but it just points to that commit and never changes
just a label for a particular commit
you just tag a particular commit as “v3.1.0” and that’s about it
and really the only occasion on which you would want to flag a new version is when some feature branch code gets merged into the master branch
so after each merge commit, there’s likely to be a tag
There are two types of tags
Lightweight Tags
just a plaintext label for a particular commit
Annotated Tags
contains extra metadeta like author name and email, time of tag, and tag message, similar to commit message
A Side Note on Semantic Versioning
Since tags’ main use case is for versioning
its important to understand proper versioning as well
SEMANTIC VERSIONING IS A SOFTWARE STANDARD
like a standard software can be observed to comply to.
there’s a defining document and all that
Semantic Versioning consists of three numbers
v1.2.3
1 is the major release
2 is the minor release
3 is the patch
for patch changes, the changes should be small and should not disturb or break existing functionality
the minor releases will include new features and moderate changes, but still retain backwards compatibility
the major releases are where large changes are made, features are removed, and backwards compatibility is broken.
the 1.0.0 version is when the official, public-facing API is defined. So if there’s not a complete public release that non-devs can be expected to use, it’s not 1.0.0 yet.
Viewing & Searching Tags
git tag
running this command will print a list of all the tags existing in the current repo
you may see a ton of tags
they either start with v or they don’t
make sure you’re consistent!!
you can run git tag with the -l flag (L)
and it will do the same thing. redundant
but if you want to search
you can run
git tag -l “*beta*”
the * is a wildcard, so any character or number of characters
and so you’re looking for all tags with beta in it at any point
*beta would imply that you want it at the end
beta* would impy you want it at the beginning
the -l flag is necessary for this searching function
so searching like “17” will get you nowhere
but “v17*” will get you all the v17 releases
Comparing Tags With Git Diff
you can git checkout by tag as well
git checkout usually grabs a branch
a branch reference always points to the most recent commit on a particular branch
but if you want to checkout an individual commit, you’ll go into detached HEAD
I think the conditions for detached HEAD were – HEAD is not currently pointing to a commit that a branch reference is pointing to
not sure
so you can just run like
git checkout v15.3.1
and pull up that commit in detached HEAD
you can also
git diff v17.0.0 v17.0.1
in order to see the changes between two patch versions
obviously the bigger the leap in version changes the more differences there are going to be
Creating Lightweight Tags
time to make tags
instead of just looking them up, filtering them, and diffing them
the simplest way to make a tag is to run
git tag <tagname>
and that will create a tag on the current commit that the HEAD is pointing to
so
git tag v1.0.0
lightweight tags are actually frowned upon and not preferred. people like annotated tags
Creating Annotated Tags
git tag -a <tagname>
that’s the command to make an annotated tag
after you make an annotated tag, you won’t be able to see the metadata on that tag when you run plain old git tag
you have to run
git show <tagname>
Tagging Previous Commits
its easy to tag previous commits that the HEAD is not currently pointing to
git tag <tagname> <commit>
where the <commit> is the commit hash
Replacing Tags With Force
git will not let you reuse a tag and point the same tagname at another commit
in order to force it to move the tag to a different commit, we use the -f flag
git tag -f <tagname> <commit>
really the -f can go anywhere
doesn’t happen often
Deleting Tags
git tag -d <tagname>
that easy
IMPORTANT: Pushing Tags
when you push your local repo up to github
by default, tags are not going to be included
you can push up just the tags though, with
git push –tags
this will push all the new tags onto the remote repo
you can also push an individual tag with
git push origin v1.5
that is
git push <remote> <tagname>
and for –tags
git push <remote> –tags
18
Git Behind The Scenes – Hashing & Objects
What Really Matters In This Section
least important section in the whole course
not needed to understand git at all
but its behind the scenes technical stuff
the local config file and the contents of the .git folder are the most important
either way, understanding what’s going on under the hood will make you a well rounded developer
Working With The Local Config File
basic breakdown of the .git folder (there are more pieces than this)
Contents
Objects folder
Refs folder
config file
index file
HEAD file
config file
you can actually set up repo configs on three levels
system wide
globally
per-repo
the config file inside .git is the local, per-repo configs
there are so many settings it is very overwhelming
when you like
git config user.name <username>
you are editing the global git file
but you can also do that within a repo for local changes
so you can have a different username/login for a specific repo
git config –local user.name <username>
the git config options are so flexible, you can even pick colors for the terminal text
could get really in the weeds on that
doesn’t get anything done though
Inside Git: The Refs Directory
refs folder
branch pointers
tags
etc
all are stored and exist inside the ref folder
refs/heads is another folder
theres a file for every branch in the repo
these files act as the branch pointers
the files just contain the commit hash of the commit they’re pointing to
it’s not that complicated
but it is specific
so if you have three branches in your repo
you will have three files in the refs/heads folder
refs also has folders for remotes
and a folder for tags
in the remotes folder
there are further folders for each remote
and the HEADS for each remote tracking branch on the remote will show up as a distinct file
again containing just the hash of the commit of the branch reference
Inside Git: The HEAD File
head is in the .git folder
it contains a reference to a branch pointer
HEAD can also be referenced to a particular commit hash
HEAD should be matched with a branch pointer
if HEAD is not matched with a branch pointer, it is said to be in detached HEAD
if HEAD is not detached
the file will contain something like
ref: refs/heads/master
that is, it will be pointing literally, to the file in the .git subfolder, of the branch reference pointer file containing the commit hash
a reference to a reference
if you git checkout <commit-hash> and enter detached head mode
the head file will contain just the hash and nothing else
the branch reference is unchanged. head points somewhere else. to a commit directly rather than a branch ref file
Inside Git: The Objects Directory
another folder worth discussing
the core of git, all the files and contents and commits
this is the meat
the objects subfolder will contain a bunch of directories with 2 digit hex folder names
the files inside are named after commit hashes
the file contents are encrypted binary files to stay very small, so VSCode and the other editors can’t render them
There are 4 main types of git objects
commit
tree
blob
annotated tag
these are the four things that get stored in the objects directory
these things will be hashed (encrypted)
contains all the data
everything else in all the other folders is just an elaborate network of pointers
A Crash Course On Hashing Functions
TIME OUT – TALK ABOUT HOW HASHING FUNCTIONS WORK
all commit hashes are 40 digits long – hex numbers
Hashing Function Definition
hashing functions are functions that map input data of some arbitrary size to fixed-size output values
Cryptographic Hash Functions are a subset of hash functions that have these characteristics
One-way function which is infeasible to invert
Small change in input yields large change in the output
Deterministic – same input yields same output
Unlikely to find 2 outputs with the same value
there are a few popular hashing functions that people use
SHA-1 is the one git uses
it always produces 40 digit hex values
but its a bit outdated and they want to migrate to a new HF
but they don’t know how or when they’ll do that
Git As A Key-Value Datastore
all 4 object types in git are hashed
not just commits
git is a key value datastore
we give it data
it hands us back a key
we use that key to later retrieve that content
its like a coat check
but for data
the key is the SHA-1 hash
the value is the data you give it
key-value datastore
that’s the format
you give it data
it gives you a key
you give it the key
it gives you the data
it can store any sort of data
Hashing With Git Hash-Object
you can just manually hash random shit using git
git hash-object <file>
and it’ll run SHA-1 on it
you can run git hash-object anywhere, not just in a repo
just as you can run git init anywhere
because your machine knows git
echo “hello” | git hash-object –stdin
you can add a -w write flag to the git command to make it store the hash key
it’ll create a new object folder in .git/objects
the first two digits of the hex number that comes out of the hash
are the name of the folder within objects
so if there are two commits/objects that start with the same two characters, they’ll be in the same subfolder
we can manually hash stuff with git
Retrieving Data With Git Cat-File
how to manually get it out
git cat-file -p <object-hash>
the -p is for pretty print
so the cat-file is the command, and when you give it the object hash
it’s not reversing the hash function. the whole point is that can’t be done
what it does is checks if it has that hash anywhere in the objects folder, and if it does, then it’ll return the file associated with that hash
git is version control
so as soon as you make even a small change to a file,
the hash it produces after the change will be completely different
keep in mind if you’re doing these manual hash commands and stuff, you’re not making any commits, just updating objects in the objects folder
git log will return nothing
the objects folder will store every version of every file
albeit in an encrypted and compressed version
so as long as you don’t delete the .git folder, everything will be retained
Deep Dive Into Git Objects: Blobs
Blob stands for
Binary Large Object
this is the file type Git uses to store the contents of files in a given repo
Blobs do not include the filenames, just the contents of a file
Deep Dive Into Git Objects: Trees
blobs just hold contents, not even filenames
when you have nested folders and hundreds of files
git changes dozens and dozens of folders, files, structural relationships, etc.
tree objects store the contents of a directory
all the pointers to other blobs and other trees
if there is one folder and one file in it
there is one tree pointing to a blob
every entry in a tree
is a tree or a blob
and then it has the hash for that tree or blob
and then the filename
trees are the structure
blobs are the substance
every commit reference is a tree
every commit refers to a tree
every tree refers to a number of trees and blobs
subtrees ultimately refer to blobs
git cat-file -p master^{tree}
will print out the tree for the tip commit of the master branch
you can also input a hash and ask git if it exists as a tree or a blob
git cat-file -t <hash>
and it’ll return
blob
or
tree
Deep Dive Into Git Objects: Commits
commits are another type of objects contained in the .git/objects folder
blobs are the simplest
trees are a bit more complicated. they point to other trees and blobs
commits are more complicated still.
commit objects combine a tree with contextual information about that tree
it contains a hash for a tree (the full folder of a particular version of the repo)
it contains a hash for the parent commit (the previous commit’s hash)
it also contains the author, and the committer as distinct entries
as well as the commit message
the main tree of a commit
has a different hash
from the commit itself
the commit is a distinct object that gets its own hash
it points to a tree, which is another distinct object with its own hash
annotated tags won’t be covered, but they’re just another type of git object, so you can guess how they’re going to work. it doesn’t really matter that much
19
The Power of Reflogs – Retrieving “Lost” Work
What Really Matters In This Section
ref log
not re flog
one his favorites
good to know to get yourself out of sticky situations
nothing is critical, you can google this in a time of need
good for recovering deleted or lost commits
Introducing Reflogs
the references
the tips of branches and the HEAD
they change from time to time
as we add commits and stuff
the ref log
is a log
of references
it tracks the changes to each of the references
The Limitations of Reflogs
reflogs are local only
they are not shared with your thousands of collaborators
the reflogs are local because you don’t need to know that someone switched branches in some specific order
reflogs also are temporary and expire entries after 90 days
The Git Reflog Show Command
git reflog show HEAD
git reflog show
git reflog show main
there’s also git reflog expire/delete/exists, but those are typically not used by end users
you only need to know about show
git reflog show will actually show you commits the head used to be pointed at that have been since deleted
stuff that git log will not show you
when you git reflog show HEAD
every relocation of the HEAD pointer will be listed since the beginning of the repo
so it’ll go down to like HEAD@{56}
similarly the branch input will show you the branch reference’s history
Passing Reflog References Around
name@{qualifier}
this is the syntax for referring to an entry in a reflog
git reflog show HEAD
or
git reflog show HEAD@{10}
will show you everything from the beginning of time for HEAD all the way up to HEAD@{10} and no further
no real reason to do that
but note the difference between
HEAD~2
and
HEAD@{2}
HEAD~2 refers specifically to two commits prior to the current commit HEAD is pointing at
whereas
HEAD@{2} refers to whatever HEAD was pointing at two changes ago
so if you switch branches, HEAD changes, and no new commits are made
if you switch to another branch, and then back again
HEAD@{2} will refer to the exact same commit that HEAD is currently pointing at
one is HEAD-travel based
the other is commit-history based
again, this is why reflogs are local and expire
its like your browser history
Time-Based Reflog Qualifiers
rather than specifying like, two entries ago, 10 entries ago
you can run it like
git reflog master@{one.week.ago}
also
1.day.ago
3.minutes.ago
yesterday
Fri, 12 Feb 2021 14:06:21 -0800
and so on
remember, only the movements on your local machine, from the last 90 days. nobody else’s
and then you can
git checkout master@{1.week.ago}
will put you in detached HEAD on whatever commit master was pointing at at the time closest to exactly 1 week ago
Rescuing Lost Commits With Reflog
you can do a hard reset and lose some commits, but retrieve lost data
you can run
> code .
to open VS Code in a particular folder
git reset –hard <commit>
will force rewind the repo
but that information is still technically available in the repo
if you git reflog, you’ll see you still have access to the commit the HEAD was pointing at one change ago, before you did the reset
so you can git checkout and enter detached HEAD to go check out those commits that have been deleted in the hard reset
you can also
git reset –hard master@{1}
and that will forcibly move the tip of the master branch to be the commit referenced in the command
that’s how you rescue a deleted commit,
you can only do in on local
Undoing A Rebase w/ Reflog – It’s a Miracle!
rebasing rewrites new commits and deletes the old commits
but those old commits from before the rebase can still be accessed using reflogs
even if you rebase and collapse 5 commits into a single commit
when you show the reflog, you’ll still see all those 5 commits from before
that commit is still stored in the objects directory, with trees and blobs and such
it’s not part of the main commit history that we normally use though
reflog gives us the pointers we need to check out old discarded commits that are not part of our official commit history
when you hard reset a branch pointer onto a discarded commit, you are ripping the pointer out of its context, and slapping it onto a commit you found in the trash
however, each commit object also refers to its own parent commit
so by hard resetting onto a commit found in reflog that’s been discarded from the official commit history,
you’re effectively dragging the whole chain of trashed commits out of the can and putting the branch reference onto its tip,
this disembodies the new work and functionally swaps it into the trash instead
so you kind of trade the new work for the old work
but again, 90 day limit
also, you can rerun the command like git reset –hard master@{1} and undo the undo you just did
reflog and rebase are very powerful
20
Writing Custom Git Aliases
What Really Matters In This Section
some people are so into their own aliases they don’t know how to use the stock git commands
nothing critical in this section though
The Global Git Config File
each repo has a local config file
git looks for the system wide config file at
~/.config/git/config
to change from the CLI
git config –global
you can open the global config file if you don’t want to set aliases via CLI
the global config file is stored at
~/.config/git/config
or
~/.gitconfig
it will be in a hidden folder in your home directory
Writing Our First Git Alias
you can make abbreviated shortcuts for specific commands
either because those commands take too long to type
or because you want to create a shortcut to a compound command with say, a bunch of really specific flags
you just open the config file, local or global, and create an [alias] entry
from there
[alias]
s = status
l = log
p = push
so then you can just type
git s
instead of git status
and it’ll work fine
Setting Aliases From The Command Line
git config –global alias.showmebranches branch
is the CLI method of creating an alias
under [alias]
showmebranch = branch
recall it’s <custom alias name> = <stock command name>
Aliases With Arguments
so if you want an alias for commit, which requires an argument
git commit -m -> git cm
and then your message will just append the commit message to the end of the alias
so like
git cm “commit message 1”
super easy
Exploring Existing Useful Aliases Online
lots of blogposts and reddit posts about peoples favorites
some for formatting git log with colors and fancy spacing and stuff
these are actually pretty sweet
gives additional functionality and saves time
useful, for log formatting at least
if you put an ! in a git alias, that tells git that it’s a shell script
so you can run shell scripts in the terminal in your git aliases as well
so people can run like grep and cat and stuff
Visual Studio Code
Preview
Write up TOC
9 hours of content
18 Sections
229 Videos
Regigigias
Notes
Rotom
Custom Drag Chain Anchor
shaft opening – 6.476mm
bolthead opening – 9.904mm
Channel System Redesign
New Measures
from PATH
offset +/-3 and +/-7 to create light path and walls respectively
channels are 6mm and walls are 4mm thick
extrude 2 to make a 2mm thick floor
reselect wall bubbles on same sketch and extrude up 30
paste in rail sketch and sweep through
highlight intersects and reverse extrude 18mm to floor
select bubbles on floor and Extrude with OFFSET: 16mm, extrude 4mm
check channel depth is 10mm
cap the ends of the channels, 6mm
punch out drop holes for wires
flip upside down, create sketch on underside
project path, then offset 1.5mm each direction
extrude to carve wire slits
Notes from first sloppy test piece
slow down first layer significantly for better accuracy
stop using that specialty adhesive, the flaking results in warping
slow down the top layers for a better finish
bridging is fantastic
new dovetail looks and feels perfect
entire print feels totally rock solid
new rails are tastefully bulky
sides are smooth and nice
top of rail is great too
new rail has 50% more area too
try increasing the slit to 4mm
consider recessing roof of female joiners by another 0.25mm
or trimming 0.25mm off of the males, since females are already thinning
rounded EDGES????
LiDAR BJJ
Initial Idea
Idea
LiDAR scans
Deep analytics for pro
High quality vods for TV review
Combine with body scan tech
Pay to record
Charge to retrieve
ML on movement patterns/body perimeters
Scanners in ever gym, ubiquitous tech
Licensing, install, SaaS
Blood & Data
Can download movement patterns from specific fighters into NNs
Integrate into VR for training & drilling, at least for striking
Yet another Massive Data Harvesting operation
Solve for bodily kinetics. Force of impact and energy delivered on every strike in every fight
Natural linkages to insect protein and skull scanning
Also connects to providing medical data as injuries and breakages occur.
Also naturally extends into sports optimization in all areas
Move fast and ride wave – new opportunities in age of AI
Utility won’t be obvious at first – data>knowledge>wisdom pyramid
Cursory Research
Finding some MMA Statistics & Analytics for fight records, accuracy and such
But no ML Body Scan type stuff
s
https://www.mma-ai.net/
Most ML/AI things are being used to predict winners
https://www.betmma.tips/flyingtriangl3
Digital Marketing
Sketches
top pages on LED NEON SIGN
ads
30day traffic
happywires.com
<1k
crazyneon.com
45k
makeneon.com
23k
ahaneon.com
25k
organic
customneon.com
80k
yellowpop.com
103k
Plan
vscode course, start python dailies, then proceed
review each book
youtube – what is marketing
chatgpt session
senator absolute beginner playlist
regroup
Notes
What Is Marketing
Seth Godin – Everything You (probably) DON’T Know about Marketing
https://youtu.be/BPK_qzeH_yk
Marketing is the process of communicating the existence of offers
The process of communicating to clients and customers A solution to their problem
The value of a brand is how much you’re paying extra from the substitute (the next cheapest generic one, sort by price). If you’re not paying extra, you don’t have a brand.
Brand Marketing and Direct Marketing are fundamentally different. Only direct can be measured and must be measured
If you work with the culture, it’s easy. Going against the river is extremely hard
The optimal way to get a lot of clicks of to act like a porn site. And marketing races to that bottom
That’s using direct marketing to rope in a significant enough number of suckers
Racing to the top entails using Direct when you should, and then relying on Brand the rest of the time
Brand Marketing is what makes the culture better, rather than worse
Tortoise hare dichotomy
Appeal to early adopters – people who are willing to play with new ideas n in the culture
Brand is steak over sizzle. Find PEOPLE WHO CARE and give them WORK THAT MATTERS
Demographics vs. Psychographics
There’s a complete spread of the psychographic spectrum within every zip code. What do you believe in and what are your dreams. Vs. who are your parents and what car do you drive
You don’t have any business as a marketer unless you have empathy for the people you are seeking to serve
Start as a marketer by finding people who want what you want and believe what you believe
You need empathy if it’s not who if already are. You have to imagine and assert what they’re going through
People don’t know what they want, they know what they dream of
The factory isn’t that important anymore, you don’t have to defend it. Everything is just a click away, so focus on “How do I solve this person’s problem?”
Attention used to be cheap. Now we pay for a shard of people’s lives, a thousand at a time
“Everyone” is not the goal. “Someone” is
Do it for the people who want me to do it with them.
Invest in better, not more
Don’t be All-truistic. Be some-truistic. Pick a select group of people and obsess over solving their problems/helping them
Limited time. Only 10 of these. Etc. when you emphasize quality over quantity you create scarcity. And scarcity creates additional value
Infinity is not your friend. If you get 1M views, don’t focus on getting 2M. Focus on making that 1M even happier to click
People make decisions based on status. Who eats first, who is on their way up, etc. And those decisions influence the culture.
If marketing is informing people of the decisions available to them, then you necessarily influence the culture
What is Marketing Today? With Seth Godin
https://youtu.be/vrJY85dBJLc
altMBA
marketing used to be a side-effect of the factory
now, marketing is at the core
unless you make coal or oil
An amazing product that no one knows about or cares about isn’t amazing because we don’t get to use it.
“Modern marketer”
internet is not mass media, it’s micro media
you have to buy tiny slices of space
attention, trust, and connection
understand your why – sinek
the why is usually very general/vague
who are you seeking to serve, figure out how to make things better for them
if you succeed, you’ll get to do it again
convert attention into trust, and then convert trust into a brand
This is Marketing Summary – 7 Animated Ideas (by Seth Godin)
https://youtu.be/i2IprdEHQgg
Do NOT make a key and then look for a lock for it
1. Find a lock, and then carefully fashion a key. The opposite is 1000x harder
2. Build Frequency & Trust
3. Permission is the opposite of Spam. Permission Assets
Isn’t the brand value just someone’s stamp of approval?
Like if Angel could stamp shoes at the store and say they’re good
That’s all the Nike brand really is
4. Brand Value
5. Status is a primary driving force
Keep in mind how the Product affects the Status goals of their customer
sometimes, customers want to decrease or maintain their status, rather than increase it
because they want to fit in, or to be outliers, etc.
Status is a primary driving force
6. Nobody Needs Your Product
they don’t want a 1/4″ drill bit, they want a 1/4″ hole.
show them why your drill bit will give them that hole
7. Direct Marketing is different from Brand Marketing
Seth Godin’s ‘This is Marketing’ Tips & Strategies
https://youtu.be/VhVHOAFshHw
marketing: people like us do things like this
managing the network of associations in the collective consciousness
his argument is that we’re all practitioners of marketing
we’re all amrketers
we buy what we want, because we already bought what we needed
we don’t want a 1/4 bit, we want the feeling of a clean room because of the bookshelf – safety, belonging, comfort
all that marketers do is Change People
they succeed by seeing people the way they hope to be seen
opening doors for them to go where they want to go
See people the way they want to be seen, and facilitate their fulfillment of that
You Change People
Status Driver
there’s a tension if you say yes or no
when they say yes or no, there’s tension because they’re deciding whether they’ll change or not
The decision you inform and present as a marketer gives the customer an opportunity to change themselves. The Marketer creates that tension and plays with it. The customer releases the tension.
Tension and Status
some humans track Affiliation, some others track Domination
It’s okay if I’m not doing well as long as the other guy I’m up against is doing worse – Dominance
Unsettling: We have to seek the smallest viable audience
The smallest market we can live with – obsess over those 100-1000 people
be ready to say “oh okay, it’s not for you”
make something special for a few – only has to be a few people
Micromedium – many millions of micromedia
Marketing is our chance to make things better. It doesn’t have to be a scam
Introduction To Marketing | Marketing 101
https://youtu.be/8Sj2tbh-ozE
understand what and why people act
persuade and influence human behavior
marketing isn’t advertising, but advertising is marketing
marketing is a major business function
advertising is a subfunction
what is the nature of marketing?
the first thing they teach you in school is the 4 Ps
Product Price Place Promotion
Communicating value to customers
the best product or service rarely wins.
the one with the best marketing, by definition, is the one that wins
Creating value for customers
Marketing itself could be valuable
a blog post that provides useful info, or an ad that makes people feel good
Good vs Bad Marketing
hypy, spammy, salesy, icky
fake countdown timers, etc.
good marketing makes people feel good and solves their problems
Introduction To Marketing | Business Marketing 101 – MOZI
https://youtu.be/Cr0KdqZ954c
3 things you should pay attention to
CAC – cost of acquisition
how much does it cost to acquire a new customer,
includes EVERYTHING
sales commission
ad spend
marketing team
software costs
LTV – Lifetime Value
total profit from a customer, lifetime
if you only profit $70 off a $700 sale
and your CAC was $200
then you’re spending $200 to make $70 – won’t work
most businesses are nonprofit LOL
30D CASH
aka Payback Period
how long does it take to pay back the CAC for a customer
virtually every business can gain access to a credit line
CCs are interest free for the first 30 days usually
these credit lines are available to front the cost of the CAC
(use other peoples money)
30D CASH is specifically
how much money each customer gives you within 30 days
if it takes them 120 days to give you the full LTV, how much of that are you getting in one month?
LTV : CAC ratio > 3:1
Try to keep LTV/CAC above 300% at all times
Remember, LTV is Gross Profit
if your customer is worth $1000 lifetime, and you profit 80% of that
then your CAC should be no more than $266
then if you can keep 1:1 CAC and 30DCASH
that is, if you are recouping the CAC with the 30DCASH from each customer
Then you can use other peoples’ money to acquire customers, since its within 30 days and CC’s don’t take interest for <30 days
Digital Marketing 101 (A Beginner’s Guide To Marketing)
https://youtu.be/h95cQkEWBx0
need strategies to get results
digital vs traditional marketing
digital marketing
larger audience – billions online
audience targeting – extremely selective
most cost effective
immediate feedback – fast feedback loop
immediate feedback, correction, etc.
everything is measured and tracked as well
results & costs, optimization on the fly
take advantage of this
core four
model market message media
model is your business (model)
market is people you’re going to serve – be focused
ideal customer avatar – whats it look like
message –
connect with your ideal target market
talk directly to them about their pains and figure out how and why you’re uniquely suited to solve
advertise your case studied
understand what makes them tick and how to talk to them
media – where you’re going to do your marketing
what channels?
figure our exactly where your target market is online and active
and put your energy there
–
tactics are the details, the executable low level stuff
what frequency, what tactics, whats the schedule, consistency, meme content, etc.
what time of day to post?
there’s a moment when you look into a new field where many of your assumptions are actually correct or close to correct, but you may not realize it. as you dive into this new field, those assumptions are tested and quickly corrected. they might get corrected into the wrong by a rare or incidental result though, so I like to watch surface level videos like this where I don’t learn much and get bored, because it provides reinforcement and structure to the parts I already knew so I’m not so quick to second guess them. Many of the fundamentals are well understood in the absence of early trauma
organic vs paid
facebook, insta, google, etc.
algorithms favor paid, because they make money – lol
people who say their marketing isn’t working are using the wrong tool for the job
Search vs Discovery marketing
the difference is intent
what is the reason they use a specific platform?
Search – when someone comes on google, they’re there with intent – you want to show up in front of them to solve their problem: SEO
you have their attention, be direct
Discovery – when users are casually browsing and you happen to show up
You might get their attention, be more subtle
there’s a difference between marketing products and services
most marketing advice is regarding products
services are intangible and need to be marketed in a different way
services require more trust because they’re usually paid in advance
products can be shown, services are a bit more complicated
marketing for services is about highlighting the current pain and emphasizing the outcome and final state
B2B vs B2C
significant differences when you’re advertising to businesses vs end consumers
b2b more incentive to put punch behind the pitch since your net is smaller but the fish are fatter
3 Steps To Starting (Or Fixing) Any Business
https://youtu.be/RZbpSe9pdFs
just give so much they’d feel stupid saying no
people keep trying to solve issues that don’t exist
don’t worry about getting too many orders if you have no orders
in the beginning
just create flow
three steps
CREATE FLOW
MONETIZE FLOW
THEN ADD FRICTION
don’t think scale if you don’t have a sale
just sell the world and deliver
they will only remember how you made them feel and how well you understood their problems
your solution should be presented as
unique
easy to understand
easy to believe it will work for them
don’t accept poor outcomes
when you have money and you have a business, then you have something to optimize
clock rate is LOW!!
give away the farm in order to generate that flow
Senator We Run Ads – Marketing Foundations Course
Digital Marketing Course – Introduction to digital marketing (Video 1)
Contents
1
Introduction to Digital Marketing
after this foundation course, you’ll be ready to become an expert in one of the modules covered
surface treatment
Marketing Funnel
Awareness
Interest
Consideration
Intent
Purchase
tell people that uber is launching in egypt – awareness
how many people click that ad about the launch – interest
if you want to buy a car, who is in your “awareness bucket”?
get in their buckets
get in their consideration bucket!
digital advertising/marketing is ~$0.5T
ROAS
return on ad spend
directly measure the success of the marketing budget
benefits of digital over offline
optimization not realistic offline
investment is lower
measurement is possible and precise
customization per user is very granular
targeting is the same thing
global reach easy
you can run a campaign for just a day or a week or two weeks to test and collect data
wondering how psychographics are quantified and conveyed
Metrics!
Awareness is measured in
Impressions
Reach
Engagement is measured in
completed views
traffic to website
app installs
app engagement
Conversion is measured in
Leads
Sales
Re-activating Audience
phases
1. generate awareness
2. generate engagement
3. close sales
three different campaigns with three different objectives
parallel to what ive heard
lead generation
lead nurturting
closing sales
2
Digital Marketing Lingo
What is Performance Marketing
digital marketing focused towards generating measurable results
i thought this was implied
but specifically pragmatic and measurable execution of digital marketing
Digital Marketing Team Structure – tasks and responsibilities
Brand
SEO/Website
Creative
Content & Social
Performance Marketing
this specifically is what I figured I’d be learning
everything else feels incidental
this is the skill that produces quantifiable results
analytics & data etc
examples include
campaigns to
generate more dr appointments
restaurant generating more food orders
etc
good performance marketer needs to understand everything from the creative design stuff to the technical and analytical stuff
CMO seems more valid after listening to Seth Godin talk about how marketing is more important than the factory today
its more like a hierarchy of production
a surplus of factories leads to marketing being the driving force of market order
CRM and MarTech
Key Terms
Advertiser
if the publisher is the TV network that has a certain number of ad slots
then the advertiser is the one buying those ad slots
treat it like inventory
facebook and google have an inventory
a stockpile of ad slots, quantified amounts of human attention for sale
advertisers are the ones purchasing this inventory
Publisher
publishers are digital asset owners who have content which the audience consumes and is capable of selling slots within this content for advertisement
the publisher is the TV network, they sell slots on the show for ads
consumption domains
websites
apps
online streaming
youtube
facebook, etc.
if their objective is to monetize their content, they are publishers
they either make content on their own website about their offers
or other people make ads about their offers to put on someone else’s website
facebook and google don’t create their own content
they only host other peoples content
Ad Network / Agency
middleman between advertiser and publisher
because i am small, no advertiser will work with me directly
but a big publisher partners with me – google adsense
now their ads show up on my small website
GDN – Google Display Network
list of 2 million companies that allows google to host ads on their sites
Google is acting as an Ad Network
google charges advertisers, takes 60% and gives 40% to the publishers
Tech Platforms
KPIs?
metrics
sometimes primary and secondary
Buying Models
CPM
cost per mille, per 1000 impressions
most used
CPC
cost per click
CPI
cost per install
CPA (acquisition)
cost per lead
like when they give you their email after clicking the ad
CPL
also cost per lead
CPD
cost per day
homepage takeover
when theres an ad on the top of a homepage of a site
masthead is the same as homepage takeover – different name
Revenue Share
types of adverts
B2B
business to business
B2C
business to customer
but goes through dealers/retailers
D2C
direct to consumer
no middleman for distribution/fulfillment
B2G
business to government
What is a CRM?
A Customer Relationship Management (CRM) system is designed to store and manage information related to customers, sales, and other interactions that a business has with its stakeholders. The specific data stored in a CRM will vary depending on the business’s needs, industry, and the functionalities offered by the CRM software. Here’s a list of common types of data stored in a CRM:
Customer Information
Personal details: Name, address, phone number, email, etc.
Company information (for B2B): Company name, size, industry, address, etc.
Contact history: Dates, reasons, and outcomes of past interactions with the customer.
Preferences and interests.
Sales Data
Opportunities: Information on potential deals or sales.
Leads: Potential customers or clients that may be interested in a product or service.
Sales transactions: Details of past sales, including products, quantities, and prices.
Sales pipelines: Stages of the sales process for each opportunity.
Communication History
Emails: Archived emails between the company and the customer.
Call logs: Notes and timestamps from phone calls.
Meetings: Dates, times, purposes, and notes from meetings.
Marketing Information
Campaign details: Information on marketing campaigns, such as emails, advertisements, etc.
Customer responses: Details on how customers reacted to marketing efforts.
Segmentation: Grouping of customers based on various factors like buying behavior, demographics, etc.
Customer Service and Support
Support tickets: Issues or problems raised by customers.
Resolution status: Progress and details on how an issue was resolved.
Feedback: Comments and suggestions provided by customers.
Contracts and Agreements
Details of any contracts or agreements between the company and the customer.
Products and Services
Information on products or services purchased by the customer.
Warranty or service contract details.
Interactions on Digital Platforms
Web analytics: Pages visited, duration of visit, etc.
Social media interactions: Comments, likes, shares, etc.
Financial Data
Billing and invoicing details.
Payment history and status.
Notes and Documents
Notes taken during interactions.
Attached files, proposals, presentations, and other related documents.
3
Digital Marketing channels
Impressions
what is an impression?
every time the ad is rendered, even if it doesn’t appear on the screen
counted as many times as it appears
billed for every 1000 renders
most commonly used metric bought and sold for marketing campaigns
Viewable Impression
subclass of impressions
ads that were probably actually seen by a user
if your ad renders at the bottom of the page, then nobody scrolls to the bottom so what are you paying for
at least 50% of the ad was continuous onscreen for 1 second
40-80% of your impressions were viewed is a good benchmark
An interstitial ad is the one that blocks you from seeing the webpage while its up
Reach
number of unique users ad was shown to
reach is always equal or less than impressions
frequency = impressions / unique users
100 impressions, 40 people = 2.5 frequency
reach is a common KPI for exposure campaigns
10m impressions, 1m reach = each person saw it 10x
brand safety includes making sure your ads don’t show up associated with content related to sexual abuse, drugs, alcohol, etc.
you can also specify things like – don’t show the user the same thing three times in one day – otherwise hatred develops and ruins the Customer Relationship
spec maxes, mins, frequencies, etc.
Clicks
whenever someone clicks the ad
doesn’t matter if they actually make it there
people who land on website are counted in Traffic
clicks always less than impressions
avg is 5-10 clicks per 100 impressions – google ads at the top of search
avg 1/100 people click on display ads – non google searched
5% for search result
1% for incidental discovery
CTR – Click Through Rate
clicks per impression
Higher CTR is better, more engaging ads
needs investigation if higher than 5%
use this to do A/B testing
Views
Youtube ads – 30 seconds or end of video or clicks
Facebook ads – 3 seconds
Twitter ads – 2 seconds
VTR – View-Through Rate
% of impressions that result in a view (ad)
VTR is how engaging the first part of the ad-video is
10-20% is normal for youtube
Bounce Rate
bounced users are those who don’t click anything on the website
they either close the page or click their bookmarks/type something in
no interaction with the page
high bounce rate means you either need to change your ad or your website
high bounce rate is bad
Anything below 50% is good
Conversion
% of people who performed a desired action on the page
Formats and Channels
its all about marketing message to your target audience
a channel is the medium you’re using
snapchat, etc.
a video campaign will be effective for a brand launch
shopping ads are a good channel if you’re an ecommerce company
list of popular channels
Paid Channels
SEM
search engine marketing
also known as PPC
paying google to show your ads
google has 90% market share of search engine
google ads aka adwords
google search is a special channel because its users have the highest level of intent
SEM guy does keyword and competitor research
run and optimize PPC campaigns
plan and optimize deliverables
Display
image banners for ads you see on websites
some of the oldest internet ads
if its not displaying price or discount information and its just a picture of the product, it’s not a shopping ad
static image in banner elements in HTML5
good for contextual website advertising or audience targeting
can retarget users if they click it, it’ll show them again
IAB Interactive Advertising Bureau
They set the IAB Standard Banner Sizes
Sizes
300×250
MPU
300×600
Half Page
728×90
Leaderboard
970×250
Billboard
160×600
Skyscraper
Video
Videos you find in the corner of the webpage being annoying
overlay ads
bumpers – 6 second ads
skippable/nonskippable
video is more effective than a banner because more information can be conveyed
some video ads are rewarded – think apps with ingame rewards for watching an ad
App
SMM
Shopping
google shopping ads
only used by ecommerce websites
triggered by keywords
appears on google search and shopping tab, some partner websites
Programmatic
Affiliate
Influencer
Audio
NonPaid Channels
SEO
ASO – app store optimization
SERP – search engine results page
factors that influence SEO ranking
secure and accessible website
page speed
mobile friendliness
domain age, url, authority
links
social signals
real business information
if you have an SEO guy
his job is to up your ranking
increase CTR
and track broad search trends & viral memes
c
SMM
Email
Content
PR
“what is your media mix?”
Programmatic Advertising Basics
RTB – Real Time Bidding
DSP, SSP, DMP
Open Auction, Preferred Deals, Programmatic Guaranteed
Programmatic Advertising is – data driven ad buying and selling using real time bidding
one of the most technical aspects of digital marketing
Data Driven
DMP – Data Management Platform
contains data about the customers/audience, so advertisers can be targeted in their buys
Nike, as the advertiser, wants to target users flagged as interested in shoes in the DMP data bank
Ad Buying
Old method worked like this – industry development
Advertisers & Publishers
Ad slots are the inventory
Publishers sell it, Advertisers buy it
Before a representative from each company would meet and discuss terms
over time, it got too hard to track all the potential clientele from both sides
This gave rise to Ad Networks – they clumped together the inventory they got from publishers
Consolidation of inventory across the industry
GDM is the biggest one – all the websites that are partnered with google
Advertisers then started talking to the Ad Networks directly
after the rise of ad networks, the advertisers were then struggling to keep track of all the ad networks
Ad Exchanges emerged that did the same thing ad networks did to publishers – consolidate their inventory
they also worked with publishers directly
stupid development
so now publishers divvy up inventory amongst several ad networks, and then ad exchanges became the interface between the advertisers and the consolidated inventory
the software for Advertisers to work with ad exchanges was called DSP – Demand Side Platform
Adx -> Ad Networks software was called SSP – Supply Side Platform
similar to buying and selling stocks
Adx is a google product, short for google ad exchange
so basically
Advertiser uses DSP on Adx to buy ad slots
Publisher uses SSP on Adx to sell ad slots
Chart
A1
->
DSP
->
AdX
<-
SSP
<-
ADNet1
ADNet2
<-
P1
P2
P3
Programmatic Advertising is a mode of buying ads
3 modes for transacting inventory
Advertiser can use DSP to ask for a proposal from a specific publisher
1 – PG – Programmatic Guaranteed
One advertiser to one publisher – “PG – Programmatic Guaranteed” 1:1/A:P
What used to be a meeting is now automated
2 – PMP Private Marketplace aka Preferred Deals
Publisher can create a proposal for distribution to a select number of advertisers
“I only want apple, samsung, and nike ads on my website”
PMP – Private Marketplace N:1/A:P
3 – RTB/Open Auction – Real Time Bidding
Publisher sells inventory to anyone – open season
Creates a spread of available ad packets
Can create some select restrictions for company or content genre
RTB/OPEN AUCTION – Real Time Bidding – ALL:1/A:P
Real Time Bidding
3 – RTB/Open Auction – Real Time Bidding
Publisher sells inventory to anyone – open season
Creates a spread of available ad packets
Can create some select restrictions for company or content genre
RTB/OPEN AUCTION – Real Time Bidding – ALL:1/A:P
Examples
Advertiser
Nike
DSP
DV360
Ad Exchange
Google Adx
SSP
Google Ad Manager
Publisher
BBC.com
in today’s world, advertisers are clever and only spend if they want to get result
DOOH – Digital Out of Home
This is when you buy ad space on screens that are outside, screens on buildings, in elevators, etc.
No production hours and dollars like there used to be for billboards, installing the gigantic printed banner
A/B testing is possible on digital billboards, etc.
Programmatic DOOH – Use DSP and book billboards on building on wall st. etc.
ads on bus stops telling you 2minutes till next bus, try our app
informative and useful, while also advertising
or a mcdonalds ad that lets you know the weather, etc.
when you book these ads, you can see where they are and stuff
You can also create conditions on the ad display like
Flights delayed -> show restaurants and hotels
Traffic Jam -> Calming App
Temp Up -> Cold Coffee
Temp Down -> Hot Coffee
Lunch Time -> Restaurant
DV360 does not have open auction
Impression Counting
Publisher Impressions vs. Served Impressions
if on an outdoor billboard – you buy a 15 second timeslot 10x
The publisher will apply a multiplier to scale the impressions by the approximate number of people who physically saw the digital ad at the time of day it was shown
so rather than getting 10 impressions for 10 renders
you’ll get like 20,000 impressions because it was rendered 10x in front of an average of 2,000 people each time
You will be charged based on the 20,000 number
The publisher sets the multiplier in your contract.
They even have cameras to track who looked at the billboard when
the best way to predict the future is to create
the best way to model consumer behavior is to drive it
Connected TV = CTV = Over the top = OTT = Digital TV = DTV
All the same concept
Roku ads
Most of the CTV inventory is bought and sold using programmatic
also includes consoles
Advanced Channels
Social Media
Organic and Paid
it has become important to have presence on these channels
the 9 basic videos reel i have saved
Organic strategies
they have a content calendar
contains the dates, platforms, contents, categories, tags, authors, etc.
cross platform schedule in a huge excel sheet
oragnic social media reach has been going down every year. more and more the media market is predetermined rather than organically grown
Which platform is better for ads
most people say facebook, because it has the most reach
but
audience targeting
format
audience concentration
determine which platform will work best
if you run a b2b – linkedin will be the most profitable
you can target certain people working for certain companies
twitter is also good for targeting people by career
snapchat for teenagers
more about SMM
what is an ad manager account? – facebook online tool for managing ad campaigns
content calendar – excel sheet
content pillar – samsung will have a fixed rotation of topics they post about
content pillar example
Day of week
Topic
1
Promotion
2
Business Benefits
3
Tips & Value Adds
4
Customer Testimonials
5
Promotion
6
Tips & Value Adds
7
Quote/Inspiration
there are tools for scheduling posts as well
socialbakers
sproutsocial
hootsuite
socialpilot
Email Marketing
1st party – when you have the emails yourself, they were given to you specifically
newsletters, signups, registrations, etc.
3rd party – when you rely on third party sources of email databases
you launch a course, and you want to send it out there
you go to a digital marketing university – ask them to send it to the emails of the students
or DM agencies, etc.
email marketing is great if it’s first party, most people aren’t fans of 3rd party
email metrics
open rate – % of people who open the email
click rate – amount of people who clicked something after opening
bounced emails – people who just left after opening
spammed emails – filtered or manually flagged
Email Automation
traditional vs automation
workflows and rules
automation tools
systeme.io
good for creating flows and logics
mailchimp
with systeme you can schedule wait 3 days then send x email then wait 2 more days then send y email
if someone clicks your course and doesn’t buy it, send them an email 24 hours later to ping them to buy it
Affiliate Marketing
if you help amazon sell something
if a youtuber reviews a product and its sales increase, he gets a commission
the promoter is the affiliate
the promoter receives a commission
the company is using “affiliate marketing”
his blog post has 30 tools for DMers
the links on them are affiliate links, he gets a commission
He uses a website called Impact.com
they show his metrics on affiliate link revenue/commissions
In order to do affiliate marketing, you need an audience
If you don’t have an audience, there is no point
Other Channels
Audio Advertising
Spotify ads
Influencer Marketing
platforms and management companies
combination with affiliate marketing
can you give us a shoutout in your video and talk about us for a minute?
then they charge us for their platform
Maybe the whole video is about that company – veritasium
App Marketing
DSPs, App Campaigns
you use your app to promote or sell products
ubereats gets 90% of its orders from its app
So they run campaigns to get more people to install the app
the link goes to the app store – not their website
4
Digital Marketing audience
5
Market research and competitor analysis
who does market research?
strategy team / entry level jobs (fodder work)
why do market research?
good starting point
your strategy should be in line
fix the existing issues, highlight the roadmap
identify issues ahead of time, define a path forward, etc.
what does market research consist of?
macro market trends in business and media
client audit
who is the client?
profile them carefully
who has the problem and what are they like?
what ads are effective at reaching them?
competitor audit
what are the competitors doing to solve the problem?
what are their ads doing?
good to use google trends for this sort of thing
case study – market research for tekla
benefits and challenges of recent move to Saas
marketing objectives, business objectives
market overview
construction work in the middle east by country
revenue of specific firms in middle east
industry revenue overall over the last few years
barriers to implementation for the specific type of software offer you have
current players/competitors in this software offer
priorities of customers desires in this type of software offer – problems you can solve that other people aren’t solving
brand and competitor audit
the competitors brand presence on each network: FB/ig/linkedin/youtube/twitter
vs. your brand presence on each network
sometimes you need to match their numbers, sometimes you can capitalize on a market they aren’t hitting
infer the strategies of the other companies by analyzing their ad campaigns on different platforms
are they using well designed assets? are they minimizing distractions? do they have clear CTA?
how are they adapting their content to each platform?
deeper dive into competitors
how many users to their website in the last 6 months
how much came from search? [SEO]
how much came from google ads? [PPC]
how important is youtube? etc.
from case study
93% of B2B marketers use bloc posts as content market tactics
B2B with blogs generate 29% more leads
89% of SaaS users turn to youtube to learn
this means your saas company should create excellent learning content on youtube
Once the market has been reviewed, the competitor audit is completed
time to audit the client itself
Client Audit
google real estate needs to be used wisely
utilize sitelink extensions (subdirectories on a google search result)
When you bid on particular keywords, make sure the ad copy is more engaging than the organic alternative
Dynamic Insertion in google ads is where you can automatically insert a keyword into the search result heading
but if you do it wrong, your link will contain the name of your competitor – you give them free advertising
and because it’s not actually going to the competitor – you look like spam
keyword strategies are important
for example: “revit alternatives” is where you should show up
but not “revit” on its own
youtube content can be optimized using metadata, better thumbnails, and adding chapter sections to the video
hashtags have to be selected and kept
if your hashtags are inconsistent, it won’t work for you
Needs to be QA on content – don’t use stupid hashtags or say stupid shit
Tools for Market Research
Statista
Similar Web
Facebook Ad Library
Google Trends
Social Blade
Hootsuite/GoogleSearch
SEO Audit
these tools are how you do the audit
Similar Web
you can type in a website or an app and see a ton of traffic metrics
bounce rate, pages per visit, avg duration, global rank, country rank, category rank
summary of the company itself, etc.
you can also see demographics on these people
M/F split, age range
categorical interests
You can get the paid version for deeper insights as well
Like similar webpages that function as competitors
or other websites that are clustered by their users
you can also see top keywords that contribute to their traffic
recently seen ads they’ve ran as well
social network distribution – traffic contribution shares
it will also show you their adtech stack
like google analytics, vs the microsoft version, etc.
you can also bring in multiple websites/companies and compare them side by side for all these metrics as well
Statista
huge repository of bar graphs with statistical information
Most used social media platforms in the UAE in 2022, by user share, etc.
Paid version lets you download pdf and such, but free version you just screenshot it
Facebook Ad Library
amazing tool?
lets you search what kinds of ads each page is running
like, nike, or nike football, etc.
you can see all the ads they’re currently running
you can see what platforms, its ID, what date it started running
if an ad isn’t working, the advertiser won’t run it for more than a month usually
so if you look up someone else’s ads and check out which ads they’ve been running for 3, 6+ months. something about those ads is working
you don’t have to search by a particular account either, you can just query a topic like google, and see all sorts of ads on jewelry or whatever
Social Blade
Say you need to look up your competitors for your digital marketing courses
lets you get huge amounts of analytical data on a youtube channel
will even estimate earnings and show you additional subscribers and views you received day by day the last 30 days
supports many platforms, including facebook as well
Google Trends
search trends on google, by geography, demographics, date ranges, etc.
only shows a graph relative to the highest peak in recent memory
no absolute numbers on search quantities
Hootsuite
Also provides a bunch of statistics and infographics like statista
SEM Rush
paid tool, using
SEOptimizer
SEO optimizing tool, tells you whats good and what needs work on your presence
keyword consistency, webpage formatting advice, etc.
what is wrong with your landing page
go to others landing page
see what they do
do something similar
Google Search
you can also just intentionally search your competitors and look at the ads they have first hand as a customer
Audience
what are audiences
groups of users with common characteristics that can be identified and targeted via ads
every business has an ideal client, a particular audience they can prospect
example
Luxury Goods
Male, age 28-45
People who like Luxury Watched
People interested to buy a real estate property
Frequent business class flyers
Users with Abandoned Carts
Parents & Flying to Dubai
what kind of people do you have in mind?
That is your audience
a population of people filtered by clustered characteristics
a segment of people with common interests
you will learn from experience what can be targeted and what cannot
you will also learn from experience how to target people in specific ways
why are audiences important in DM?
audience size can be higher than some countries populations
audience analysis and selection means your marketing campaigns will have higher efficiency
save money on the budget and have higher conversion rate
thus it’s an optimization & data driven thing
how are audiences identified?
Cookies
user profiles on web profiles
Device IDs (IDFA, ADID)
identifier for advertisers (iOS)
Android ID (Android)
Phone Numbers & Email IDs
note that the audiences are composed of DEVICES not PEOPLE
so a breakdown of your IDs might be
Desktop cookie
Mobile Cookie
Google AD ID
Apple IDFA
what does audiences consist of?
at this point, just understand that an audience list is just cookied, device IDs, phones, and emails
1st party, 2nd, 3rd
party status is determined by who owns the data and who uses it
1st
email
phone
website visitors
CRM
owned and used by the person
most reliable and efficient
2nd
city registration, telecom, airlines, hotels, etc. databases
A deal between two companies where data is given out.
uncommon, paid, reliable and relevant
unlike the oracle example below
it’s when the one who uses the data buys it directly from the collector
so if booking.com sold info directly to atlantis hotel
3rd
parents, age groups, about to buy a car
common, sold by adtech companies
reliability varies,
needs expertise to be relevant
booking.com collects data about users
oracle buys this data from booking.com as well as thousands of other websites
consolidate and aggregate all the data so it can be sold to advertisers who can make use of it to produce better ad targeting.
then advertisers like atlantis hotel buy this data from oracle
audience mapping and sizing
how do we target people who will be interested?
Sample Chart
Platform
Targeting
Reach
Google Search
Keywords
30k
Facebook
Interested in: Age Group:
100k
YouTube
Video Genre, Age Range
40k
LinkedIn
Industry, Type of Job, etc.
22k
targeting your audience is slightly different on each platform
and so determining the number of people who will be interested will be a unique process – mapping
along with this, there will be a different number of potentially interested people in each network for a particular offer – sizing
this is all part of a process called Media Planning
Try it yourself:
Diesel is launching their new fragrance for ladies and is priced at $200
what keywords should be targeted on google?
If you have to target certain facebook pages, which pages?
Audience and Persona
Audiences provided by platform
Demographics
Age band granularity varies by parents
somtimes you can figure out if someone’s a parent or not
tiktok wants to target teenagers – anyone under 35
demographics’ importance varies by the offer
there are cases where a woman will buy a product marketed for a man as a gift, but it’s not worth spending ad dollars on
feedback loop – if 90% of your sales are coming from age 18-24, then pivot your marketing strategy to favor them
you can also target by income range/percentile
don’t target bottom 50% if you sell something expensive, and vv
demographics is all about cutting people out of your focus
Behavioural
affinity
affinity audiences
groups created based on interest in a certain topic – flagged based on the type of contact they interact with
example – football fans – people who interact with football content online – devices that click football links
interest = affinity
google has affinity audiences
facebook has interested audiences
other examples – watersports enthusiasts
motorcycle enthusiasts
if you need to sell tickets for a rock show – market to young people in the area that are flagged as rock fans
sportswear/healthy lifestyle, etc.
in-market
affinity means somebody consumes content
in-market means they are in the purchase journey, looking to buy something
watching videos doesn’t necessarily mean you’re shopping
in market is a HOT LEAD – they are looking to buy
they will be going to a lot of websites shopping around, filling out lead forms, etc.
in market is more valuable
custom intent
similar audiences-lookalikes
this secondary or peripheral audiences are created based on their interest and behavior from a seed audience
useful for expanding reach
new terminology could be “targeting expansion” or “optimized targeting”
so basically, narrower targeting or second-order targeting
getting more and more specific
you give google an audience and tell it to sort within that audience
HVA – high value audience
people in the audience that spend the most money in a time period, week
similar audiences is not available on google as of mid 2023 – tracking issues
workarounds have been made using that new terminology
Remarketing/Retargeting
list of users who have visited your website and targeting them again is called retargeting or remarketing
we’re talking
cart abandoners
non-converters
new offer/re-engagement
Upsells
this is how you get someone to buy the thing in their cart – send them a coupon after a few days so they actually buy
remember, CAC
Platform Specific Audience Types
page engagers – facebook and instagram pages
only target people who engage with your page regularly
meme accounts that sell shitty t-shirts every news cycle
only really available on facebook/ig
followers of specific profiles – twitter
you can create audiences based on followers of a particular account, or cross section of several accounts
if you follow elon musk and aoc – i sell you funko pops
there’s no way to target nationalities of people directly – but there are creative ways to figure out what the nationals do online – like follow their PM
industry and job title – linkedin
target only doctors, for your webinar for doctors
What is Persona
some companies call it avatar
it is a hypothetical profile of the audience you want to target
mentions their demographics, behaviour, and other details like education, status, etc.
you can have multiple avatars or personas based on the diversity of your audience
ed is a 28 year old software developer who got a degree in CS from a state university. he does not have many friends, he has lots of disposable income, no girlriend, is very insecure, and likes to golf and ski. we should sell him a motorcycle
personas are a tool for segmenting their target audience into chunks so they don’t spread themselves too thin – create substrategies for each persona
if you have a construction/architecting design SaaS business
you might have the four personas to market to
Engineers & Architects
Owners/Contractors/Decision Makers
Clients of the Contractors
Students of the Industry
you’ll have to spin it differently for each of them
Additional Terminology
intent
inmarket is high intent
low intent is prospecting
intent level is how interested they are in making a purchase
if they just want to consume content, they are low intent
if you are trying to buy a home and you have your down payment together, you are a high intent prospect
Some Tools for Audience Analysis
SparkToro
search for audiences that talks about “Drones”
or “3d printers”
other words they use, hashtags, keywords, etc.
also shows other interactions: certain websites, follow accounts, youtube channels
also shows what they listen, watch, and read – podcasts etc.
my audience follows xx account
Audiense
has a lot lot lot of info about the audience
Crystal AI
any linkedin profile you go to it’ll show you additional information about them
Lead Feeder
can connect google analytics and feed in the traffic from your website into lead feeder
lead feeder will literally figure out who’s on your website and tell you what company they work for
my b2b business – i can see all the visitors’ place of employment so i know their business is interested in my product
DMP – data management platform
1st party is app store, excel, salesforce, webpages
3rd party is visa, netflix, booking.com
DMP is an audience data store
3rd parties provide data into the platform as well
everybody pools their data together so their campaigns are more effective
CRM – customer relationship management
salesforce is an example
how they remember you the second time you go to the dealership
CDP – customer data platform
tealium is an example
stores all the data from CRM
but also event driven data and traffic from website/socials, etc.
unlike DMP, CRM and CDP only contain 1st party data
the difference betwen CRM and CDP is getting blurry lately
6
Digital Marketing channels – Google Ads
Google Ads
0:00 Introduction
everything about a google SEARCH campaign from start to finish
0:48 Introduction to Google Ads
$146B revenue from ads for google in 2020
Google Ads is the mother of all online ad platforms
as well as the most powerful platform for online advertising
Every other platform is derivative of google ads’ model
you can work on any platform if you understand google properly
probability of high intent is much higher on google
if you search a particular product name, you’re more likely to be looking to buy it
you can track how much you spent and how many sales you made
SEM (paid search results) is not a replacement for SEO (organic optimization)
You do both
What types of ads can we run on google ads?
Eight types
Search
search results
Display
graphics on webpages
Shopping
search shopping results
Video
video ads on youtube can only be run using Google Ads and DV360
App
App install ads
similar to a display banner – but goes to the app store
Smart
shows up on search, maps, and on webpages. more automated
Local
drives customers to a local destination
Discovery
run ads on gmail, youtube, search
visually rich, personalized, drive engagement
22:11 Create Google Ads account
restaurants might spend $25-50 a day and make a profit on local ad campaigns
now small clients can use advertising tech instead of just the big ones
your campaigns will not run unless you have a card in there
make sure you switch to expert mode
if you ever do DM for different clients, make sure they all have unique accounts
A Google Ads Manager account lets you manage multiple google ads accounts at once
you can see all accounts’ campaigns’ performances at once from the same dashboard
or if you have multiple marketing campaigns within the same operation
grant access and control to others, consolidate billing, etc.
google ad manager account is closer to current ux in vid
34:46 Hierarchy in Google Ads account
Hierarchy
account manager
ads account
campaign
ad group 1
ads
keywords
ads need keywords
an ad group has bidding, ads, keywords, targeting, budgets, etc.
campaigns have dates, budgets, objectives, type
ad accounts oversee performance, billing, global control, etc.
whether they search for best dentist or veneers, you should show up
keyword-ad optimization
Segment your campaign into several ad groups based on specific services that are searched with distinct keywords
ad group – keyword cluster
example ad groups
group name
keywords
Ad Copy:
Max CPC:
1
brand ad group
toyota dubai
awr dubai
ai rostamani
2
car sales
buy car
new car offer
toyota yaris price
3
services
replace car battery
car garage near me
oil change garage
increase your max CPC for premium services
you’ll spend way more money on ads to get someone to buy a car – it’s worth more
individual ads cannot have multiple landing pages
ad groups allow you to segment, so you can take people to different landing pages
ad group 1 targets men with a picture of a man using your product
ad group 2 targets women with a picture of a woman using your product
51:50 Start your first Search campaign
the rest of the google course will be treating etoro as a sample client
fintech life
dashboard has clicks, conversions, cost per click, and total cost for time period
you can load in existing campaign settings
when creating a search campaign
you have options to include the google search partner network and the google display network in your campaign.
if you just want to do google search results, then don’t do these. it’ll just cost you more money. remember to be specific
google can autogenerate display banners from your text for the search ads
but to do this kills the purpose of the campaign. just do a display campaign if that’s what you want
you can search audiences
set by city or country, or set a radius around a pin
once you have a specific location
you can target presence or interest or both
presence – they’re in that area regularly
interest – they’re searching for that area
you can also exclude presence/interest in your area
when you set the language, it’s tracking the device’s browser language setting
if you don’t set english, it does all languages by default
for search campaigns, audience selection does not mean anything
1:27:20 Bidding strategies in Google Ads
naming conventions for bidding strategies change often
this will determine the success of your campaign
first, set the daily budget
the daily spend will fluctuate but the monthly average will not exceed the number
make sure the credit card has funds – if it gets blocked even once google ads will not let you use that card again
google offers a credit line
bidding – what do you want to focus on
select a bid strategy directly – there are 7 automated bidding strategies
there is a manual option but the automated ones are so good there’s no point
The 7 are
Target CPA
Target ROAS
Maximize Clicks
Maximize Conversions
Maximize Conversion Value
Target Impression Share
you can set a price you’re willing to pay to show your ad for each individual keyword
$1 for neon signs
$2 for custom led neon signs
and so on
Terminology
Impressions
# of displays
Clicks
# of displays clicked
Conversions
filling out a lead form, making a booking, or making a purchase
Cost
Amount spent on advertising
ROAS
Return on ad spend = sales generated/cost %
CTR
Click Through Rate = Clicks/Impressions %
CPC
Cost per click = cost/clicks
CPA
Cost per action = cost/conversions
some people know google ads as CPC because google only charges when someone clicks
the selection of one of the 7 bidding strategies and the justification behind it determines the success of the marketing campaign. it’s also the first interview question you’ll get asked
Learn Them By Heart!
Bid Strategies
Strategy
What it does
How it works
Target Impression Share
Increase visibility on google
Automatically set bids to show on search results page on a certain position
Maximize Clicks
Increase Website Traffic
Automatically adjusts bids to get maximum possible clicks within your budget
Target CPA
Get more conversions within your target CPA value
Set bids to get conversions within specified CPA value
Maximize Conversions
Get most conversions while spending your budget
Set bids in a way to get maximum conversions. Whole budget will be spent.
Target ROAS
Target a ROAS value. Useful when every conversion is valued differently
Set bids to keep a target ROAS
Maximize Conversion Value
Get more conversion value/dollar spent
Set bids to get maximum conversion value. Whole budget will be spent
Target Impression Share – we should be on top of google. i don’t care if they click or not . Build Awareness
google will ask if you want top of page, first page, etc.
Maximize Clicks – primarily just for generating traffic. no conversion objective. Building Awareness & Engagemen “Nurturting”
Target CPA and Maximize Conversions are both for people who are optimizing for conversions
Maximize Conversion – Burn it all, get it all – Sports Mode
Target CPA – Economy Mode – fuel efficiency, go for mileage
You can set up a rotation for your ads
optimize, to prefer best ads, or don’t and just keep rotated
optimize for conversions is also an option
1:59:12 Ad Extensions
There are 11 types of ad extensions
List of Ad Extension Types
1
Sitelink
Sitelink is the subdirectories within the search result
Takes up the most space on the search result
up to 6 on desktop and 8 on mobile ad
Sitelinks are to give users options to go to the section of your website they want to go
About/Contact us/Products/Order Form, etc.
2
Callout
highlight services and aspects of their business
USP – unique selling proposition
stuff like
Free Trial. Highly Reliable. 7 Day Free Trial. Low Fail Rate. 24/7 Support.
stuff like that
3
Structured snippet
A more structured/formatted Callout
There are a finite number of categories for these
Like, Destinations, Courses, Degree Programs, etc.
4
Image
When a google ad has a little picture next to it
Helpful for product ads
5
Call
Adds a phone number (and a call button on mobile)
6
Lead form
Adds a button to fill out the lead form
7
Location
It will include the pin and show the address of the store
8
Affiliate location
It will include the pin and show the address of the store
9
Price
Includes specific products and their prices, along with links to those product listings
10
App
Includes app install button
11
Promotion
Includes promo/discount info
Some are paid and you need to pay google to set them up
some ads have longer descriptions and can include a phone number in their google search listing
This is a phone extension/call extension
It basically adds assets to your ad
You can also add a lead form extension so from the google search listing they can fill out the form
Ad extensions
free and optional
free to occupy more real estate for your brand on google ads
takes user direct to where they want
won’t always show
CPC will be the same as them clicking on main Ad
so, more specific service, more coverage, optional, free
2:25:15 Ad Rank and Quality Score
Ad Rank
you want your ad to be at the top, it’s good for brand image to be number one
what influences it?
CPC Bid – how much are you paying for the ad
Quality Score – google automatically assesses the quality of your ad
Quality Score
no matter how much you pay, if your ad sucks google won’t put it up there
every keyword has a quality score rating
so use good keywords
high quality score keywords cost less per click
quality score is determined by
Ad Relevance
CTR
Landing Page Relevance and Quality
so it’s about keyword efficacy and alignment to effective keywords
keywords that people search
keywords that people click
keywords that you’re using
Having a good quality score results in
Pay less in CPC
Ads show more often
Ads rank better in Google SERP
google wants everything on google to be relevant
2:39:05 Ad Group Structure
setting up ad groups within campaign
helps structure campaign, segment audience, etc.
ad groups consist of dedicated ads and keywords
ad groups organize your ads by the products and services you want to provide
if you’re searching for chairs or tables and you sell tables and chairs, there should be a different ad for each
buy stocks vs. best trading platform
stuff like that
cluster the keywords and write an ad copy for that cluster, and assign them an ad group
Best Practice is to create ad groups based on your services
example of keyword clustering
Brand
Generic
Competitor
Crypto
etoro portfolio
trading platform
fx trade platform
buy crypto
etoro investor
best trading platform
IG Forex platform
best crypto trading platform
etoro platform
regulated trading platform
how to create IG Forex account
invest on etoro
trusted trading platform
Always create a sheet like this
Create a huge table of keywords, and categorize them
Always have at least
Brand, Generic, and Competitor keyword columns
Add additional columns by industry, service segment, etc.
Have another sheet for Ad copies
Ad Group
Headline 1
HL2
HL3
Description 1
D2
D3
Landing Page
Preview
brand
generic
competitor
Keep all your ad content data together in one place!!
Extension Sheet as well
Extension Type
Text
Landing Page
2:56:07 Keyword planner
how to research keywords, google keyword planner
First ad group
Pure Brand
google will automatically generate a list of relevant keywords based on your seed phrases
this also influences the estimated cost per day
google keyword planner is a paid service that is more intricate
you can see search volume per keyword as well as its bid range
advanced analytics on individual keywords
same core tool for generating keywords, keyword planner just provides additional information
three parameters you can apply onto the keywords in the generated keyword list
keyword = broad match
ad will show on searches that relate to the keyword
“keyword” = phrase match
ad will show on searches that include the keyword
[keyword] = exact match
ads will show on searches that ARE the keyword
progressively more restrictive
maybe just making the most relevant ones phrase match
seems like exact match is somewhat rare
negative keywords later
3:13:17 Write search Ads
write killer ads
keyword research
include all keywords on your list on the landing page
they should ALL be present, or your ad/keyword quality score will go down
when making an ad, google will give you a quick reference on if your ad is strong or not. like password strength
Contents of an Ad
Final URL
Display Path
15 char, not part of the actual URL, descriptive
Headlines
The first two are guaranteed to appear
3 Headlines merged together
There are certain best practices
Think like an end user
pay attention also to successful companies’ ad copies
remember that you can search and look up other peoples’ ads as well on demand
1st headline should be your brand name
try to avoid redundancy between the 2nd and 3rd headlines
use most relevant keywords in 2nd and 3rd headline phrases
use keywords and ad groups to make sure the ad doesn’t come off as generic, should be relevant to a specific type of search
approach angle
surfaces
the ads are dynamic, so the headlines in the list can appear anywhere
you can manually pin the headlines into a specific position
Decriptions
keywords match landing page match ad copies
You can create tracking urls that include a particular type of formatted suffix
You see them all the time.
3:41:12 Negative Keywords
our keyword is bitcoin
user searches for a bitcoin movie or something
so you can add movie as a negative keyword
your negative keyword will prevent your ads from running when that keyword is present in the search query
after a period of running the campaign and collecting data
you can also see search terms that pinged each keyword
so you can take that feedback and update your ads
negative keywords can be added at the campaign level or the ad group level
you have a living and growing list of negative keywords, due to your constant monitoring to make your ads ever more refined
the keywords tool category has search keywords, negative keywords, and search terms
Google Ads Advanced
0:00 Introduction
0:31 Performance Max Campaigns
an automation effort with some AI
upload some assets and select a bidding strategy
google takes care of the rest
goes through gmail, youtube, search, 3rd party, etc.
it auto generates further assets and splits across media platforms
its complementary with normal search campaigns
they do not compete when your exact match keywork from the search campaign is eligible in the performance max campaign
they won’t bid against eachother
not appropriate to run alongside anything but a search campaign
to make a performance max, make a new campaign
just throw it 15 images, some logos, videos, text, and it takes it from there
personalizes headlines for end user as well
after it generates, you can review what it comes up with and tell it no
after selecting the generative assets for each category of ad, you just have to define audience segments and its good to go
can filter people by their demographics and their keyword searches
performance max campaigns are probably the staple of the future
15:46 Conversion and Remarketing pixels
Conversion Pixels
helps count conversions
optimizes campaigns
if you don’t have conversion pixels set up, you won’t be able to create remarketing lists
Steps
Generate Conversion Pixels
Put them on Landing Page
Test to ensure
Create conversion pixels entails providing a specific url for the conversion action, and then setting up tracking on the google backend
When the conversion involves the customer making a purchase, it is useful to assign a $ value to the conversion
using no value is fine if you’re just collecting data
different value is useful when transactions are variable
you can also count every single conversion, or just one per user
click through conversion window means
if they become a conversion at any point using any pathway after clicking that link, it counts as a conversion for that link
makes sense, since i often come back manually
keep attribution model as data-driven, unless you have a whole tech team for this stuff
once you set up these conversion actions, implement them on the website
either edit the website code, email the webmaster, or use google tag manager
looks like you can just inject the html into the header – via html edit or just wordpress
the first step is to implement the google tag code in every page on the website
the other snippet goes into the thank you page at the end of the conversion process
the options are 1. thank you page load or 2. button click
those are the conditions for the conversion to be counted
now how do you test it?
you can add a chrome extension to googletag assistant legacy
It’ll show you the google tags in the code for the page you’re on
it won’t show you all of them, just the ones associated to your account?
conversion pixels is one of the most complicated topics
multiple codes, need to pass values around, etc.
make sure you get it
36:18 Remarketing campaigns
how to set up,
when to set up
how to in google
important considerations
for remarketing campaigns
statistically, average conversion rates around 2-5%
remarketing campaigns have much better prospects
target only people who have already visited your website
the second or third pass works
it’s just like catching a horse!
why do they have higher conversion rates?
they were already interested, second try works
but if they weren’t interested in the first try, why try again?
maybe they were busy? give it another shot
maybe they need to do more research
remarketing is also a reminder that, maybe hey you left stuff in an abandoned cart maybe you should buy it
industry practice is 80-90% is for the original search campaign
10-20% for the remarketing campaign
you can only do remarketing campaigns if you have conversion pixels set up
remarketing campaigns are usually display and/or video
if budget is tight, just do display
display campaigns have content exclusions – you can make it so your products don’t show up near tragedy and conflict, senstitive social isues, etc.
if you’re looking to get max conversions, put in the CPA at 3x current, and then slowly draw it back
it’s once you get to targeting and audience segmenting in the campaign setup that you can make it into a remarketing campaign
in audience, you can tell it to target specifically all visitors of your website
you are retargeting everyone who goes to your website for any reason, even if they were never served an ad
get Penji.co
unlimited graphic design for a fixed monthly rate
will produce ad assets for you
literally $500/600 a month
customize retargeting assets – make it feel personalized and targeted
do not serve them the same ad a second time, if you have the means to create remarketing assets
more things
Dynamic Retargeting
if a user has looked at a product on amazon
later they’ll see an amazon ad showing THAT EXACT PRODUCT
that’s cool
Exclusion of Converters
you can waste your money on targeting people who already converted.
exclude these people for better marketing efficiency
OR
retarget them differently for upsell stuff
laptop sleeves, etc.
Custom Remarketing List
Multiple Sources like Email IDs, Phone#s, Device ID
1:00:00 App Campaigns
google ad campaign trying to get them to install apps
or to increase engagement/playtime in app
UAC – universal app campaign = UA = User Acquisition
Separate for iOS and Andoird
Firebase and MMP(AAP)
lots of terminologies for apps
UAC is google name for app campaign
DMers call it UA
separate campaigns for android and iOS
separate them
Firebase is analytics for apps, another google tool
MMP is a mobile measurement partner
third party providers, do the same thing, analytics tool
lets you see how many people opened the app, what actions they took, total playtime, new users, new installs, # of purchases, etc.
youalso get to know the source oftraffic for installs and conversions
you can also create events on the app and such
create audiences segmented by responsiveness to the events and so on
Firebase
Kochava
Apps Flyer
Adjust
a handful of tools
in google ads, there are 3 app campaigns
app installs, engagements, and pre-reg
pre-reg is android only
install is a vanity metric, doesn’t mean much for revenue
if they don’t use it or don’t buy things on it it’s not that valuable
App campaign
1. setup conversion, and audience for UAC engagement
2. launch campaigns
3. report and optimization
setting up conversions for app campaigns is the same as the conversion pixels we went over earlier
Android apps are easy to set up conversions for in google ads due to integration with the google play store
it makes it very easy to track installs and in-app purchase
the three tracking options are
1. firebase
2. google play integration
3. 3rd party app analytics
ACE and ACI are more terms for engagement and installs
still UAC
when you get to bidding for apps
you can focus on install volume, etc.
you can also target specifically users who are most likely to perform an in-app action
or just all users
very little audience targeting options for app campaigns
6 seconds is a good length for ad video
remember that Android and iOS app campaigns are distinct
no difference between them, just have to be set up independently
UAC Engagement campaigns are different from UAC Install campaigns
get people to spend more time on app
people who haven’t ordered ubereats in 30 days or something like that
create that audience before you create the engagement campaigns
1. App Users
Users have been active recently
Users who took a certain action
Users who haven’t taken a certain action
2. Device IDs
Upload
Push through your CRM
3. Firebase Audiences
only ADID or IDFA – device IDs can be used
remember, you can’t target people, only devices
marketing is about buying and selling ad space, which as acting as a proxy for buiying and selling attention/soul/lifespan, but even that is just a proxy for device activity
souls can be mocked
recall that some device IDs might be like 6 years old and will represent devices that are disabled unused or broken. old phones people don’t use anymore
though you can probably update a customer profile with other data like email or phone# when you see their device ID update
not looking forward to reviewing and summarizing this whole course, it’s kind of scattered all over the place
deeplink is formatted like
ubereats://
ubereats://?c=offer1
Google app campaign ads will appear
google search
app store
google properties, gmail and discovery
youtube
GDN websites and apps
GDN includes apps
7
Important channels
8
Web Analytics
Google Analytics
UTM Builder
Microsoft Clarity
are your big three options
two versions of GA
UA – Universal Analytics
GA4 – Google Analytics 4
As of 7/1/2023 – only the new one, GA4
GA is a reporting tool
everyone can access the GA of Google Merchandise site
if you don’t have a website to integrate it with
DV360 and CM360 are both more sophisticated, paid versions
Universal Analytics, Traditional old version
UI has a master view dash board of all the analytics accounts
view lets you set up filters for quick access to specific datas
raw data view
has the filters
test view
master view
analytics accounts have “properties” that are large databases that you can use these views to interface with
UA and GA4 require distinct properties and are not cross-compatible
The main purpose of Google Analytics is to generate reports.
you can track length of visit, number of pages visited
microconversions, like who clicks the product
macroconversions, who buys
page pathing, add to carts, etc.
you can get a live feed of how many users are active on your site
as well as page views per minute, most active pages, and even
top referrals, top social traffic, and top keywords
you can see event activity in real time, but of course, those events have to be set up and defined manually
Realtime Reports
overview
locations
traffic sources
content
events
conversions
Audience Reports
Overview
users, new users, sessions, sessions per user, etc.
session length is 30 minute
so if he’s there for 31 minutes, two sessions on that user
sessions per user is at least 1.0
avg session duration, bounce rate, pages/session, etc.
avg session duration for an ecommerce site being 3 minutes is pretty good
bounce rate is probably the most popular metric
low bounce rate is good, generally
if you have log, a blog, or you share a coupon code, they’re gonna bounce, obviously
Audience data is all about user country and language
it can mean a lot to know which city your users are coming from
your day of max users will not be your day of max conversions, necessarily
most commonly used report is source/medium
direct/none is they load in directly
google/cpc means they came via ad
if your google cpc as good as your organic? you wish!
all these metrics, bounce rate, pages/session, etc.
will all be different for organic/direct and google/cpc
the URL often determines which campaign that click gets assigned to
analytics will also show you the distinct traffic metrics for each campaign
its easy to connect google ads to google analytics
Active Users
Behavior Reports
Behavior flow is important
shows where they came from, their starting page, their path through your site, and where they left
you can also see site speed metrics, maybe it’s faster on iOS, or faster in malaysia for some reason
how long it takes to load
page load time actually gets pretty granular
Explore as much as you can within the google analytics demo account
find correlations and get familiar with the tools
doing all the setup work is different work from simply pulling and exporting the reports
funnel shows people moving through conversion steps, how many drop off, where the drop off too, %s and such
the five reports are
realtime
audience
acquisition
behavior
conversions
admin settings
you can create metric goals that will help structure and inform your analytics reports
for google ads linking, or adsense, etc. it’s under admin
you just connect the ID and do some email auth
overview on home, you can see when your traffic is highest per time of day too
Google Analytics 4
set up the web stream on GA4
receive the web tag
then go implement that tag in your Google Tag stuff on the webpage
and then they’re linked together and 24 hours later your analytics should be ready to work
attribution is last click or data-driven
user can interact with several campaigns on their way to conversion
last click – last campaign. can do first click, time decay, etc.
data-driven – try to find the campaign that actually brought them in
data-driven is good for most users
google has suggested PREDICTIVE AUDIENCES
it will estimate who is likely to make a purchase in the next 7 days, etc.
admin table under GA4 is very very strong
UTM Parameters
important for analytics
anyone who comes from this facebook ad, their source will be flagged as “jimmy” or whatever
just making the sources
URCHIN Tracking manager
Google analytics was not made by google
so some stuff still has their nam,e
you need to generate a UTM tracker thing
ga-dev-tools.google.com/campaign-url-builder
builds out the url for setting the analytics metadata that you can use on the ads
takes in campaign medium, website, source, campaign name, etc.
generates a url for you to use
it takes you to the page, but the additional url junk passes parameters into the analytics database
stopping here
What’s left?
Microsoft Clarity
Reporting Dashboards
Reporting Fundamentals
Digital Marketing Project Briefing
Case Study
Toolkit
so
moving over to toolkit
Toolkit
Competitor and Market Analysis
SimilarWeb
Competitor and web traffic Analysis
Social Blade
Channel analytics
Statista
Graphs and stuff
Facebook Ad Library
Master Ad Lookup
Youtube
Camtasia
screen recorder and editor
obs?
TubeBuddy
provides analytics right on the side of every video and channel you load on your browser. browser extension. simple cursory analytics
competitor is VidIQ
StreamYard
Livestream software system. obs?
Email Automation and Landing Pages
Systeme.io
six tools to build your business
sales funnel
email marketing
online course
website building
affiliat programming
amrketing automations
looks useful
Google Forms
quiz, survey, etc.
Google Sites
easy if you need something quick and don’t want to do wordpress or domain stuff
Audience Research
Sparktoro
People use follow this account, use this word in their profile. analytics on them
Audiense
Expensive, but helps with a lot of use cases. twitter and normal insights. segmentation based on cultural affinities and such. maybe both demo and psycho
Crystal AI
Extends linkedin profile for you
Lead Feeder
tells you who employs the people visiting your side
Keyword Research Tools
Google Keyword Planner
Google Trends
SEM Rush
oHREF
Graphics
Canva
basic design tool platform
has a ton of templates for ig posts and stuff
free version
PhotoPea
basically a weblite version of photoshop
Envato Elements
Unlimited assets you can free use once you pay sub fee
Presentations and Reporting
Google Slides
ReportGarden
integrate a ton of data from all platforms
MS Clarity
has heatmaps for where people click – whole analytic suite
Supermetrics
Google Tag assistant
Facebook Pixel Helper
9
Reporting
10
Website Development
11
Creative Development and Content Creation
12
Automation and Tools
13
Media Planning
14
Strategy
Facebook Ads Course
1
Introduction
half of the world population uses a meta platform app once a day
90% of DMers use Facebook Ads
20-30 of all ad spends were on facebook in 2022
in 9 years he’s never seen someone with a marketing budget that wasn’t using facebook
if they run ads online, you bet they’re on facebook
so basically, google and facebook
Campaign Objectives
1
Awareness
New launch, offer, top of mind
2
Traffic
Generate traffic to website
3
Engagement
Increase followers, viewership, interaction, brand love
4
Leads
Generate on facebook leads easily for sales funnel, inquiries, appointments, etc.
5
App Promotion
Increase app installs, engagement in app
6
Sales
Sales or conversion based campaigns, ecommerce, etc.
awareness is good for things like dating apps, so when they have a need, they know where to go
followers are a good vanity metric to build credibility
4 types of ads on Facebook
Image
Video
Carousel
Collection
Where do ads appear?
“Placement”
These are the placement options
Facebook
in-feed
explore
stories and reels
search results
instream video
right corner
Instagram
in-feed
explore
stories and reels
search results
Messenger
home
message list
stories
Audience Network
partner apps and sites
rewarded video ads
banner, interstitial, native
Apart from lead ads which open forms within facebook/instagram
we can redirect to 6 types of destinations
Website
App
Website and App
Messenger
WhatsApp
Calls
2
Facebook Ads Ecosystem
3 ways to advertise on facebook
noob:
1. boost post
appears on your post if you’re the owner
2. promote via page
same
expert:
Ad Manager
requires setup
more functionality
Most budgets include money to boost a particular post if it performs well
You need a Facebook Profile to run ads
Then you make a Facebook Page
Ther is also a Facebook Business Manager that can hold the account, page, and ad manager all in one place
including additional user access, partners, payment methods, etc.
who owns the account?
you or the marketer you’re contracting?
as the marketer you may or may not provide them access
but giving them limited access to the business manager account is a good compromise
important concern
managing permissions for each party and employee involved on both sides of the table is important
either you’re setting up the ad manager and business manager account for them and owning it
or giving them partial ownership
or they own it and they let you into it
basically the most important thing is who’s payment methods are saved
3
Make a page
page title and headline are both very important, and contribute to SEO
you can add three tags to your page as well
make sure you provide as much contact info as possible
take all the fields seriously and fill them out as much as possible
including working hours and such
give them something to work with and make it look and feel legit for them
Content Pillars
3-5 pillars that define all your posts in one way or another
Create Facebook Ads and Business Manager Account
business.facebook.com
if you are on the business manager
or
adsmanager.facebook.com
if you are on the admanager
you can create a new or add an existing ad account
or request to share
once you set up facebook account, page, business manager, payments in business manager, and create ad account
90% of everything will happen in ad account
4
5
Campaigns
campaigns have media, objectives, budget, and flight dates
some run indefinitely
most have an end date in mind
campaign types and objectives
Resource Review
ChatGPT essential
Senator We Run Ads is a good channel so far
Looks like Google or FB Marketing Stack is necessary
Spend 5-7 days learning fundamentals, what marketing is and what it’s for
Personal MBA & It’s references to additional resources
Hormozi
Current Summary
1 Week overview
WordPress, HTML, Website Bringup
Canva, Fundamentals of Design
Probably: Photoshop & Videoedit
Google Analytics is inevitable
Google Stack: the bare minimum
Google Ads
Google Analytics
Google Tag Manager
Google Data Studio
15 mins to collect resources
can do this in 1 month
(do VS and start python course before moving into HTML)
personal mba rec books: – sorted by interest
Review: ‘All Marketers Are Liars’ by Seth Godin
Review: ‘The 22 Immutable Laws of Marketing’ by Al Ries & Jack Trout
Review: ‘Permission Marketing’ by Seth Godin
Review: ‘Getting Everything You Can Out Of All You’ve Got’ by Jay Abraham
senator we run ads absolute beginner playlist
https://youtu.be/5A4D5xnrtIA?list=PLv6KfiLx9P_3lI-RKgRARrMdhkcG041v-
23 videos, each around 30 minutes
some members only content
w3schools HTML tutorial
https://www.w3schools.com/html/
Canva
10 minute vid
https://www.youtube.com/watch?v=zJSgUx5K6V0&pp=ygUMaG93IHRvIGNhbnZh
100 minute vid
https://www.youtube.com/watch?v=un50Bs4BvZ8&pp=ygUMaG93IHRvIGNhbnZh
Setting up a wordpress online store
both vids are 2.5 hours
whoever has the less annoying voice
https://www.youtube.com/watch?v=facMcbWB0jI&pp=ygUTd29yZHByZXNzIHNob3AgcGFnZQ%3D%3D
https://www.youtube.com/watch?v=4Ncre-Uup7g&pp=ygUTd29yZHByZXNzIHNob3AgcGFnZQ%3D%3D
Google marketing stack
Google Marketing Platform essentials, by google
https://www.youtube.com/watch?v=Ew6xHvDfat0&list=PLTzhNbuEe_C9vlaBcvD2a2UCIHBLb48M-
google ads in 1 hour
https://youtu.be/a-JmhK9nKJk
google analytics
4 hours
https://www.youtube.com/watch?v=e6ntvZDErQ4&pp=ygUZZ29vZ2xlIGFuYWx5dGljcyB0dXRvcmlhbA%3D%3D
15 minutes
https://www.youtube.com/watch?v=njri8_gJTs0&pp=ygUZZ29vZ2xlIGFuYWx5dGljcyB0dXRvcmlhbA%3D%3D
Design Fundamentals
15 mins
https://www.youtube.com/watch?v=YqQx75OPRa0&pp=ygUQYmFzaWNzIG9mIGRlc2lnbg%3D%3D
Making a good landing page
30 mins
https://www.youtube.com/watch?v=zpTsCrOvGao&pp=ygUdbWFya2V0aW5nIGhvdyB0byBsYW5kaW5nIHBhZ2U%3D
Social Media Marketing
25 mins
https://www.youtube.com/watch?v=6FYVm7_5eHU&pp=ygUYdXB3b3JrIGRpZ2l0YWwgbWFya2V0aW5n
How to DM freelancing
30 mins
https://www.youtube.com/watch?v=LROBlGI8v-0&pp=ygUYdXB3b3JrIGRpZ2l0YWwgbWFya2V0aW5n
Google Skillshop
A nested set of articles on various topics about google’s tech stack
https://skillshop.exceedlms.com/student/catalog/browse?utm_source=website_17th_sep&utm_medium=uni_header&utm_campaign=get_started
Facebook Ad Tutorials
6.5h
https://www.youtube.com/watch?v=yFrrEiKLsM4&pp=ygUVZmFjZWJvb2sgYWQgbWFya2V0aW5n
40m
https://www.youtube.com/watch?v=6cwkjpYBG3Q&pp=ygUVZmFjZWJvb2sgYWQgbWFya2V0aW5n
Saved various videos on what is marketing
Seth Godin – author of the books
Youtube
how I would learn digital marketing (If I could start over)
https://youtu.be/aUerDG2SNTA
Intro
easy to get overwhelmed with all the tools, stacks, and strategies:
google ads
facebook ads
seo
smm
programmatic advertising
email marketing
affiliate marketing
growth marketing
performance marketing
content marketing
account based marketing
ad-tech
B.I.
analytics
“Drip content”
and other personal strategies and misc terminologies
1. Avoid shortcuts, and have the right mindset
enter a rabbit hole called
how to make money in digital marketing
flashy content on HOW I MADE $100/day!!!
what is the right mindset then?
spend 5-7 days on what is marketing?
don’t need academic books
just what is marketing and why do people use it?
what are the benefits, etc.
core, fundamental questions that define what it is
fundies
2. Create a blog or a website
90% of marketing is focused on taking someone to a webpage
a facebook page, a youtube page, etc.
just getting them to click
you cannot learn DM before you understand the webpage – the basic building block of the web page
how to make your website live – core task
you don’t have to understand web development
just be able to buy a domain and set up a page
google sites, wordpress, github pages, etc.
(could probably make a business just setting up cookie-cutter webpages and filing LLC’s for people)
Note: this is also literally the definition of a fundamental skill to “Build Things”
a huge overlap between building things and selling things – making a webpage
learn basics of HTML – required to be a solid DMer
w3schools – HTML tutorials
shouldn’t take more than a day or two
tech like
Ad Tags
Conversion Tags
etc.
makes it easier
3. Be an Expert & Avoid the Noise
this is where most people face problem
ok go learn social media marketing, facebook marketing, app marketing, etc…
if you want to be a strong digital marketer, that can compete with people and even be a freelance consultant etc.
you have to become an expert in something
like facebook ads, or google ads. etc.
if you understand paid media, then affiliate marketing and SEO and etc. get WAY easier
choose one paid media platform and become an expert in it
DFP he worked on exclusively for two years @@@?
Double Click for Publishers
In the context of digital marketing, “DFP” stands for “DoubleClick for Publishers.” It was a service provided by Google to help publishers manage their ad inventories and optimize their ad revenue. Here’s a brief overview:
Ad Serving Platform: At its core, DFP was an ad server, meaning it allowed publishers to organize and manage their ad spaces, decide which ads to show, to whom, and when.
Monetization: DFP was designed to help publishers maximize their ad revenue. It could do this by allowing publishers to set up rules and criteria for serving ads. For example, a publisher could prioritize higher-paying ads to appear more often or target specific ads to specific user demographics.
Integration with DoubleClick Ad Exchange: One of DFP’s strong points was its integration with DoubleClick Ad Exchange (AdX). This meant publishers using DFP could easily fill their unsold inventory with ads from AdX, potentially maximizing revenue.
Rich Media and Video: DFP supported not only standard display ads but also rich media and video ads, giving publishers a broader range of monetization options.
Targeting & Reporting: DFP provided detailed reporting tools, allowing publishers to understand their audience, ad performance, and revenue streams. It also supported advanced targeting options, enabling publishers to serve ads based on various criteria, such as user behavior, geographic location, device type, and more.
Evolution to Google Ad Manager: Google decided to merge its DoubleClick for Publishers (DFP) and DoubleClick Ad Exchange (AdX) services into a single platform called “Google Ad Manager” in 2018. So, if you hear people talking about Google Ad Manager today, know that it’s the successor to what was once DFP and AdX.
The primary reason behind this merger was to provide a unified platform that better serves the needs of publishers in an increasingly complex digital ad landscape.
its easy to learn another platform after you master one
just like coding languages, it sounds like
ok so how do we learn google ads
youtube, udemy, etc.
he has a google ads playlist, etc.
give it complete focus, don’t learn anything else – learn GOOGLE ADS deeply
google skillshop and help center help in parallel to youtube. extra resources
test skills by building stuff out even if it doesn’t go anywhere
even if you don’t go live
just like coding
create campaigns and stuff
demo campaigns
once you’re ready, try friends and family, or just go upwork
do some marketing work for free, basically
or just, for your own business, lol
4. Learn Customer Journey (Landing Pages and Design Basics)
when they go to the landing page, what should it look like?
so basically, the last 10% after you get them to click the button
so. set up a website and get people to go to it
a normal website and a landing page are wayy different
you have to learn some design tools like CANVA to get this stuff working
Display Campaigns and Video Campaigns require you to know
THE BASICS OF DESIGN!!!!
sounds like – website creation, landing page design, UX design, (the thing they’re clicking)
ad campaigns, specific tools for creating paid marketing (getting them to click)
Google Ads, WordPress, Canva, Photoshop(?), HTML, Photoshop, Video Editing
5. Learning, Reporting, and Analytics Tools
google analytics is probably the best tool
easy 1h course on google analytics to get the feel for it
he has this video
play around and learn on your own
you can also go deeper and do a 5 hour course or something
learning google analytics is INEVITABLE – no matter what you want to do as a DMer
there’s also microsoft clarity – only takes an hour or so to figure out
at this point you can probably just get a job – freelance project on upwork/f&f
next steps still though
you want to become a solid digital marketer
6. Learning Ecosystem & Marketing Stacks
all big companies have their own marketing and analytic stacks
the bare minimum
Google Ads
Google Analytics
Google Tag Manager
Google Data Studio
acquire a high level overview of one complete marketing stack, and then you can find your way through any other
get hands on experience
you can get a job as a PPC analyst/specialist.
these things have a huge impact long term
7. Taking a Step Back
once you’re an expert in one thing you need to understand the basics of everything else
jack of all trades, master of one
8. Focus on Advanced Topics
DMPs CDPs
Affiliate Marketing, Content Marketing, Email Marketing, etc.
at this point you’re probably top 5-10% in the market
at this point you can make money in your own ways
Freelancing, build an Affiliate Network, do Consulting
9. Learn Strategic Skills
know how to create a strategy with objectives for a startup or a company, or whatever
how to create a digital marketing strategy
at this point you can make a strategy for any client for any case
Playlist on his intro to digital marketing course
https://youtu.be/5A4D5xnrtIA?list=PLv6KfiLx9P_3lI-RKgRARrMdhkcG041v-
ChatGPT impact on DM
https://youtu.be/dbeFZKEXjb8
Why he quit DM 4 months ago
https://youtu.be/CGbmYex7x10
ChatGPT might replace some digital marketers
https://youtu.be/dbeFZKEXjb8
will help DMers
“give me some ideas of youtube video titles for a digital marketing youtube channel”
stuff like that
can also quickly generate talking points for each video title
“write me an ad copy for a dating app”
“write a copy for senior citizens”
nice
“what are the best digital marketing campaigns of all time”
actually pretty cool list
can be specific to auto industry/companies as well
good for extracting examples
CM360 and DV360 are two digital ad platforms
what are the differences between the two? – @@@
what are common interview questions for DM roles? – good question
Can get ChatGPT to create scenario based interview questions – good test
I Quit hustle in Digital Marketing
https://youtu.be/CGbmYex7x10
not a burnout video, just WLB stuff
Sableye
Notes
Ungar Review
First thing, I just realized, can you patent this? Might want to check that out. Even if it’s not super enforceable, it’s a good resume booster
I hadn’t considered that at all. This system doesn’t really feel like an innovation to me.
In order of thoughts as I went through:
1) Looks outdated for a website. Doesn’t feel modern
Not sure what I can do about this without rebuilding the whole thing? It’s made with WordPress+Elementor. It’s also what I use for eein.info
2) Checking on Mobile there’s a lot of scrolling to see the content
3) Lot of scrolling on website (non-mobile) as well
Good point. I’m following a template structure from a youtube video.
https://youtu.be/WgXU7XAZYmQ
4) Text for “Most of us dream in the dark” & “Light up your life”: I like it but it feels like it’s missing the oomph I think you want. Could remove the second paragraph under “most of us dream in the dark” (see screenshot)
Yeah, I’ve been rephrasing this one a lot too. I actually rewrote it to be less dramatic recently.
5) Use a carousel for the images and testimonials or a grid layout. Also, for some of the testimonials, it’s not clear where the sign is without looking at it. I might show my own image of the sign lit up, and then link to their text and instagram post.
The carousel blocks I have on the free version are a little clunky but I’ll see what I can do. I agree the signs aren’t super obvious in some of them. I think there’s a lot of value in showing the sign in-situ, rather than my gallery pic. I think a good middle ground is to only use photos where the sign is obviously the main light source and coloring the whole photo (like in the two red ones)
6) FAQ has some great into
7) “What do I need to provide to place a custom order” see screenshot. Bracketed text feels awkward and confusing. Had to re-read a lot to understand. Might say To get price all we need is a reference image/graphic and the approximate size
agree, thanks
8) “How long until I get my sign” see screenshot. But “lead” is weird in this context, it’s not a “normal” word choice. I would rephrase it to be On average it takes 4-6 weeks.
works for me
9) “Can I order a duplicate of someone else’s custom order?” – Uhhhh, this feels weird just imo. Like, do you tell people that whatever they send in becomes your property? Just feels weird and makes me think if I spend time modeling something that you then just resell it to others
This is a good point – since the landing page content is all about unique style/identity stuff. This bullet could probably just not be here. Most people just order existing logos from games and stuff. The few who have unique brands to capture, I assume there wouldn’t be anyone asking for a duplicate.
10) “How big can you make them?” – If possible it would be cool to see the 4’x12′ sign with some person or something for comparison. I know that’s huge, but seeing a person next to it or something for size comparison makes that concrete instead of “oh ya big”
Good point, I’ll take a picture with it. I also need to go at night and get a good picture somewhat in the same format as the rest of the gallery (its outside, on a wall)
——————————————————-
Image
Image
Image
Image
11) “What are the advantages of 3D Printed signs over Acrylic?” – Might be neat to have one of those comparison graphics. Where it’s the check marks of “Acrylic vs 3D printed” see image
agree, I’ll put something together
12) I would not put your phone number on there. You don’t want someone spamming you after they feel ripped off or something. Keep that private or get a work phone specifically for this.
good point
13) On the about page, you probably shouldn’t mention Angel and Vince on what their roles are. Just one of those things where it’s neat to call them out and t hank them, but they don’t need to know the exact rolls in the business right now. Just a personal thing.
I see where you’re coming from. I’ll tweak it.
14) Gallery is neat and should be shown sooner to show the signs off. Like I mentioned in #5, combine this with their own image and testimonial.
agree, see below
15) For future signs, you might want to take 5 second recordings of the sign cycling through colors. That way the gallery is more alive and shows off what these things can do
I’ve only done 2 RGB signs, and have gifs of both, so I can do this. The page won’t be that dynamic, but the few animated ones will be pretty eyecatching
16) For your instagram and twitter have those as hyperlinks
good point
17) Your logo doesn’t do you justice for how cool your work is. Why not create it as an actual sign to show off? Also consider a graphic designer for it as well.
Bruh, I did pay one of my artist friends to do this logo for me… After a handful of drafts we settled on this one. It’s simple enough, but a few weeks later I realized it’s just the Nissan logo. Also
—————————–
Overall, this is awesome. There’s a lot of little things that add up though imo but it wouldn’t stop me from ordering. I would just consider hiring someone to set it up to make it more modern and flow better.
Thanks. Organic orders/growth have stopped, so I’ve spent the last 2 weeks watching a ton of digital marketing tutorials on youtube and taking notes. The basic idea was to build a website, and start pages on other social platforms, and then do some paid marketing campaigns on FB/IG and see what I can come up with. I’m assuming paying for a webpage designer is out of my budget atm, and figured I already know 80%+ of what I need to do it myself.
Because the end goal of the site is to engage the customer, show them what you can do, show them why they want you, and then have them reach out. I feel the part of “showing them what you do” is a bit difficult in coming across when it should be much easier given how visual this is
This and #2/#3/#14, I agree. I was following that youtube template, but these signs are so visual that it makes a lot of sense to put them up as soon as possible. Maybe a mini gallery just below the landing content?
Landing Page
WordPress/Elementor
Structure
The Hero Section
The thing that annoys people most when visiting a website is Lack of Message
Strangely
What the business does and what services it provides
5 seconds
What you do
Why it matters
What they need to do to get it
Main Headline
What is the result you offer
Sub headline
Clearly explain how you give it to them, the means, the product
Call out your ideal customer type (s?)
CTA Button
anyone who’s ready to go should have an obvious path forward
actionable and specific
descriptive of what actually comes next
Results 1, 2, 3
what they can expect
what the use cases are
Image
They will look at the image for nearly 6 seconds
show the result
happy white girl using a laptop worry free with a latte
not a white dude knee deep in computer guts
They aren’t buying the thing you’re selling. They’re buying the result.
Problem-Solution Section
Pain agitate Solution
One paragraph on each
bring up the pain, main pain point
bigger
capture their attention. big thesis means they read it more
agitate that pain, with examples
introduce the solution
a video here keeps people on the page longer
also the best location for a video
Benefit section
Three Benefits with the dumb little symbols on them
most compelling three benefits are the headline
feature description in the subtitle
benefits are different from features
benefits are
benefit
feature
Stay Connected
USB-C Charging, Bluetooth
Immersive Sound
22 speaker, 960W audio system
Room for everything
90cu ft trunk
Testimonials and Social Proof
72% of customers will only take action after reading a positive review
reviews are to
overcome an objection or speak to a benefit
Keep them short
Three reviews,
ideally photos and names, real social proof
stand behind it publicly
“I have 100+ 5-Star Reviews on Google
Features
Features list is just the list of tech specs
Decisions are made on emotion first, and then back-justified using logic
This is where you give them the 10-20 technical,rational, details they need
FAQ
This is the place for common questions
but also an opportunity to defeat potential/common Objections
Write them out in QA Format as a virtual sales script
Finally, the CTA Button once again
Pancho Gyro
String too tense, trying the softer one
